


















 Download code from GitHub
Download code from GitHub
Chapter 1: Challenges in Machine Learning
Many people believe that artificial intelligence (AI) is all about the idea of a humanoid robot or an intelligent computer program that takes over humanity. The shocking news is that we are not even close to this. A better term for such incredible machines is human-like intelligence or artificial general intelligence (AGI).
So, what is AI? A more straightforward answer would be a system that uses a combination of data and algorithms to make predictions. AI practitioners call it machine learning or ML. A particular subset of ML algorithms, called deep learning (DL), refers to an ML algorithm that uses a series of steps, or layers, of computation (Goodfellow, Bengio, and Courville, 2017). This technique employs deep neural networks (DNNs) with multiple layers of artificial neurons that mimic the architecture of the human brain. Though it sounds complicated enough, it does not always mean that all DL systems will have a better performance compared to other AI algorithms or even a traditional programming approach.
ML is not always about DL. Sometimes, a basic statistical model may be a better fit for a problem you are trying to solve than a complex DNN. One of the challenges of implementing ML is about selecting the right approach. Moreover, delivering an ML project comes with other challenges, not only on the business and technology side but also in people and processes. These challenges are the primary reasons why most ML initiatives fail to deliver their expected value.
In this chapter, we will revisit a basic understanding of ML and understand the challenges in delivering ML projects that can lead to a project not delivering its promised value.
The following topics will be covered:
- Understanding ML
- Delivering ML value
- Choosing the right approach
- Facing the challenges of adopting ML
- An overview of the ML platform
Understanding ML
In traditional computer programming, a human programmer must write a clear set of instructions in order for a computer program to perform an operation or provide an answer to a question. In ML, however, a human (usually an ML engineer or data scientist) uses data and an algorithm to determine the best set of parameters for a model to yield answers or predictions that are usable. While traditional computer programs provide answers using exact logic (Yes/No, Correct/Wrong), ML algorithms involve fuzziness (Yes/Maybe/No, 80% certain, Not sure, I do not know, and so on).
In other words, ML is a technique for solving problems by using data along with an algorithm, statistical model, or a neural network, to infer or predict the desired answer to a question. Instead of explicitly writing instructions on how to solve a problem, we use a bunch of examples and let the algorithm figure out the best way (the best set of parameters) to solve the problem. ML is useful when it is impossible or extremely difficult to write a set of instructions to solve a problem. A typical example problem where ML shines is computer vision (CV). Though it is easy for any normal human to identify a cat, it is impossible or extremely difficult to manually write code to identify if a given image is of a cat or not. If you are a programmer, try thinking about how you would write this code without ML. This is a good mental exercise.
The following diagram illustrates where DL and ML sit in terms of AI:
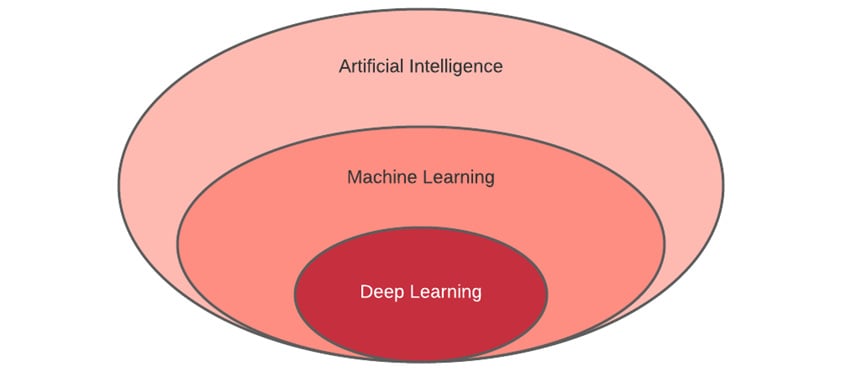
Figure 1.1 – Relationship between AI, ML, and DL
AI is a broad subject covering any basic, rule-based agent system that can replace a human operator, ML, and DL. But ML alone is another broad subject. It covers several algorithms, from basic linear regression to very deep convolutional neural networks (CNNs). In traditional programming, no matter which language or framework we use, the process of developing and building applications is the same. In contrast, ML has a wide variety of algorithms, and sometimes, they require a vastly different approach to utilize and build models from. For example, a generative adversarial network (GAN), which is an architecture used in many creative ML models to generate fake human faces, is trained differently to a basic decision tree model.
Because of the nature of ML projects, some practices in software engineering may not always apply to ML, and some practices, processes, and tools that are not present in traditional programming must be invented.
Delivering ML value
There are many books, videos, and lectures available on ML and its related topics. In this book, we will cover a more adaptive approach and show how open source software (OSS) can provide the basis for you and your organization to benefit from the AI revolution.
In later chapters, we will tackle the challenges behind operationalizing ML projects by deploying and using an open source toolchain on Kubernetes. Toward the end of the book, we will build a reusable ML platform that provides essential features that will help contribute to delivering a successful ML project.
Before we dig deeper into the software, we must have foundational knowledge, and we must know the practical steps required to successfully deliver business value with ML initiatives. With this knowledge, we will be able to address some of the challenges of implementing an ML platform and identify how they will help deliver the expected value from our ML projects. The primary reason why these promised values are not realized is that they don't get to production. For example, imagine you built an excellent ML model that predicts the outcome of football World Cup matches, but no one could use it during the tournament. As a result, even though the model is successful, it failed to deliver its expected business value. Most organization's AI and ML initiatives are in the same state. The data science or ML engineering team may have built a perfectly working ML model that could have helped the organization's business and/or its customers; however, these models do not usually get deployed to production. So, what are the challenges teams face that prevent them from putting their ML models into production?
Choosing the right approach
Before deciding to use ML for a given project, understand the problem first and assess if it can be solved by ML. Invest enough time in working with the right stakeholder to see what the expectations are. Some problems may be better suited to traditional approaches, such as when you have predefined business rules for a given system. It is faster and easier to code rules than is it to train a model, plus you do not need a huge amount of data.
While deciding whether to use ML or not, you can think in terms of whether pattern-based results will work for your problem. If you are building a system that reads data from the frequent-flyer database of an airline to find customers to which you want to send a promotion, a rule-based system may also give you good and acceptable results. An ML-based system may give you better matches for certain scenarios, but will the time spent on building this system be worth it?
The importance of data
The efficiency of your ML model depends on the quality and accuracy of the data, but unfortunately, data collection and processing activities do not get the attention they deserve, which proves costly in later stages of the project in terms of the model not being suitable enough for the given task.
The paper cited here discusses this challenge. An interesting example quoted in the paper is of a team building a model to detect a particular pattern from patient scans, which works brilliantly with test data. However, the model failed in production because the scans being fed onto the model contained tiny dust particles, resulting in the inferior performance of the model. This example is a classic case of a team being focused on model building and not on how it will be used in the real world.
One thing that teams should put focus on is data validation and cleansing. Many times, data is often missing or is not correct—for example, a string field in a number column, different date formats in the same field, or the same identifier (ID) for different records if the records come from different systems. All this data anomaly may result in an inefficient model that will lead to inferior performance.
Once you've been through this process and come to the decision that yes, ML is the way to go… what next?
Facing the challenges of adopting ML
Organizations are eager to adopt ML to drive their business growth. In many projects, the teams become too focused on technical brilliance while not delivering the business value expected from the ML initiative. This can cause early failures that may result in reduced investment for future projects. These are the two main challenges that businesses are facing in making ML mainstream in all the various parts of the business, as outlined here:
- Keeping the focus on the big picture
- Siloed teams
Focusing on the big picture
The first challenge organizations face is building an ecosystem where ML models create value for the business. The challenging part is that teams often do not focus on all aspects of a project and instead focus only on specific areas, resulting in poor value for the business.
How many organizations that we know of are successful in their ML journey? Beyond the Googles, Metas (formerly Facebook), and Netflixs of the world, there are few success stories. The number one reason is that the teams put focus just on building the model. So, what else is there beyond the algorithm? Google published a paper about the hidden technical debt in ML projects (see the Further reading section at the end of this chapter), and it provides a good summary of things that we need to consider to be successful.
Have a look at the following diagram:

Figure 1.2 – The components of an ML system
Can you see the small block in Figure 1.2? The block in the picture captioned ML is the ML model development part, and you can see that there are a lot more processes involved in ML projects. Let's understand a few of them, as follows:
- Data collection and data verification: To have a reliable and trustworthy model, we need a good set of data. ML is all about finding patterns in the data and predicting unseen data results using those patterns. Therefore, the better the quality of your data, the better your model will perform. The data, however, comes in all shapes and sizes. Some of it may reside in files, some in proprietary databases; a dataset may come from data streams, and some data may need to be harvested from Internet of Things (IoT) devices. On top of that, the data may be owned by different teams with different security and regulatory requirements. Therefore, you need to think about technologies that allow you to collect, transform, and process data from various sources and in a variety of formats.
- Feature extraction and analysis: Often, assumptions about data quality and completeness are incorrect. Data science teams perform an activity called exploratory data analysis (EDA) in which they read and process data from various sources as fast as they can. Teams further improve their understanding of the data before they invest time in processing the data at scale and going to the model-building stage. Think about how your team or organization can facilitate the data exploration to speed up your ML journey.
Data analysis leads to a better understanding of data, but feature extraction is another thing. This is a process of identifying, through experiments, a set of data attributes that influences the accuracy of the model output and identifying which attributes are considered irrelevant or considered noise. For example, in an ML model that classifies if a bank transaction is fraudulent or not, the name of the account holder is considered to be irrelevant, or noise, while the amount of the transaction could be an important feature. The output of this process is a transformed version of the dataset that contains only relevant features and is formatted for consumption in the ML model training process or fitness function. This is sometimes called a feature set. Teams need a tool for performing such analysis and transforming data into a format that is consumable for model training. Data collection, feature extraction, and analysis are also collectively called feature engineering (FE).
- Infrastructure, monitoring, and resource management: You need computers to process and explore data, build and train your models, and deploy ML models for consumption. All these activities need processing power and storage capacity, at the lowest possible cost. Think about how your team will get access to hardware resources on-demand and in a self-service fashion. You need to plan how data scientists and engineers will be able to request the required resources in the fastest manner. At the same time, you still need to be able to follow your organization's policies and procedures. You also need system monitoring to optimize resource utilization and improve the operability of your ML platform.
- Model development: Once you have data available in the form of consumable features, you need to build your models. Model building requires many iterations with different algorithms and different parameters. Think about how to track the outcomes of different experiments and where to store your models. Often, different teams can reuse each other's work to increase the velocity of the teams further. Think about how teams can share their findings. Teams must have a tool that can facilitate model training and experiment runs, record model performance and experiment metadata, store models, and manage the tagging of models and promotion to an acceptable and deployable state.
- Process management: As you see, there are a lot of things to be done to make a useful model. Think about the processes of automating model deployment and monitoring processes. Different personas would be working on different things such as data tasks, model tasks, infrastructure tasks, and more. The team needs to collaborate and share to achieve a particular outcome. The real world keeps on changing: once your model is deployed into production, you may need to retrain your model with new data regularly. All these activities need well-defined processes and automated stages so that the team can continue working on high-value tasks.
In summary, you will need an ecosystem that can provide solution components for all of the following building blocks. This single platform will increase the team's velocity via consistent experience within the team for all the needs of an ML system:
- Fetching, storing, and processing data
- Training, tuning, and tracking models
- Deploying and monitoring models
- Automating repetitive tasks, such as data processing and model deployment
But how can we make different teams collaborate and use a common platform to do their tasks?
Breaking down silos
To complete an ML project, you need to have a team that comprises various roles. However, with diverse roles, there comes a challenge of communication, team dynamics, and conflicting priorities. In enterprises, these roles often belong to different teams in different business units (BUs).
ML projects need a variety of teams and personas to be successful. The following screenshot shows some of the roles and responsibilities that are required to complete a simple ML project:

Figure 1.3 – Silos involved in ML projects
Let's look at these roles in more detail here:
- Data scientist: This role is the most understood one. This persona or team is responsible for exploring the data and running experiment iterations to determine which algorithm is suitable for a given problem.
- Data engineers: The persona or team in this role is responsible for ingesting data from various sources, cleaning the data, and making it useful for the data science teams.
- Developers and operations: Once the model is built, this team is responsible for taking the model and deploying it to be used. The operations team is responsible for making sure that computers and storage are available for the other teams to perform data processing, model life-cycle operations, and model inference.
- A business subject-matter expert (SME): Even though data scientists build the ML model, understanding data and the business domain is critical to building the right model. Imagine a data scientist who is building a model for predicting COVID-19 without understanding the different parameters. An SME, which would be a medical doctor in this case, would be required to assist the data scientists in understanding data before going on to the model-building phase.
Of course, even with the building blocks in place, you're unlikely to succeed at the first attempt.
Fail-fast culture
Building a cross-functional team is not enough. Make sure that the team is empowered to make its own decisions and feels comfortable experimenting with different approaches. The data and ML fields are fast-moving, and the team may choose to adapt a recent technology or process or let go of an existing one based on the given success criteria.
Form a team of people who are passionate about the work, and when you give them autonomy, you will have the best possible outcome. Enable your teams so that they can adapt to change quickly and deliver value for your business. Establish an iterative and fast feedback cycle where teams receive feedback on work that has been delivered so far. A quick feedback loop will put more focus on solving the business problem.
However, this approach brings its own challenges. Adopting modern technologies may be difficult and time-consuming. Think of Amazon Marketplace: if you want to sell some new hot thing, by using Amazon Marketplace, you can bring your product to market faster because the marketplace takes care of a lot of moving parts required to make a sale. The ML platform you will learn about in this book enables you to experiment with modern approaches and modern technologies with ease by supplying basic common services and sandbox environments for your team to experiment fast.
It is critical to the success of projects that teams that belong to distinct groups form a cross-functional and autonomous team. This new team will move with higher velocity without internal friction and avoid tedious processes and delays. It is critical that the cross-functional team is empowered to drive its own decisions and be supported with self-serving platforms so it can work in an independent manner. The ML platform you will see in this book will provide the basis of one such platform where teams can collaborate and share.
Now, let's take a look at what kind of platform will help you address the challenges we have discussed.
An overview of the ML platform
In this section, we will talk about the capabilities of the ML platform that you will need to consider. The aim is to make you aware of the basic building blocks that could form an ecosystem for your team to help you in your ML journey. An ML platform can be thought of as a set of components that assists in the faster development and deployment of ML models and data pipelines.
There are three main characteristics of an ML platform, as outlined here:
- A complete ecosystem: The platform should provide an end-to-end (E2E) solution that includes data life-cycle management, ML life-cycle management, application life-cycle management, and observability.
- Built on open standards: The platform should provide a way to extend and build on the existing baseline. Because the field is fast-moving, it is critical that you can further enhance, tailor, and optimize platforms for your specific needs.
- Self-serving: The platform should be able to provide the resources required by teams automatically and on-demand, from hardware requests to deploying software in production. The platform automates the provisioning of resources based on enterprise controls and recovers them once the job is completed. The resources can be central processing units (CPUs), memory, or disk, or can be software such as integrated development environments (IDEs) to write code or a combination of these.
The following diagram shows the various components of an ML platform that serves different personas, allowing them to collaborate on a common platform:

Figure 1.4 – Personas and their interaction with the platform
Apart from the characteristics presented in Figure 1.4, the platform must have the following technical capabilities:
- Workflow automation: The platform should have some form of workflow automation capability where both data engineers can create jobs that perform repetitive tasks such as data ingestion and preparation and data scientists can orchestrate model training and automate model deployments.
- Security: The platform must be secured to prevent data leaks and data loss that can have a negative impact on the business.
- Observability: We do not want to run applications without observability, whether it is a traditional application or an ML model. Deploying applications in production without observability is like riding a bike blindfolded. The platform should have a good amount of observability where you can monitor the health and performance of the entire system or sub-system in near real time. This should also include an alerting capability.
- Logging: Logging plays a key role in understanding what happened when systems start behaving in an unexpected way. The platform must have a solid logging mechanism to allow operations teams to better support the ML project.
- Data processing and pipelining: Because ML projects rely on a huge amount of data, the platform must include a reliable fully featured data processing and data pipelining solution that can scale horizontally.
- Model packaging and deployment: Not all data scientists are experienced software engineers. Although some may have an experience in writing applications, it is not safe to assume that all data scientists can write production-grade applications and deploy them to production. Therefore, the platform must be able to automatically package an ML model into an application and serve it.
- ML life cycle: The platform must also be capable of managing ML experiments, tracking performance, storing training and experiment metadata and feature sets, and versioning models. This not only allows data scientists to work efficiently, but also allows them to work collaboratively.
- On-demand resource allocation: One important feature an ML platform should have is the capability that allows data scientists and data engineers to provision their own runtime resources automatically and on-demand. This eliminates the need for manual requisition of resources and eliminates time wasted on waiting and handovers with operations teams. The platform must allow platform users to create their own environment and to allocate the right amount of compute resources they need to do their jobs.
There are already platform products that have most, if not all, of the capabilities you have just learned about. What you will learn in the later chapters of this book is how to build one such platform based on OSS on top of Kubernetes.
Summary
Even though ML is not new, recent advancements in relatively cheap computing power have allowed many companies to start investing in it. This widespread availability of hardware comes with its own challenges. Often, teams do not put the focus on the big picture, and that may result in ML initiatives not delivering the value they promise.
In this chapter, we have discussed two common challenges that enterprises face while going through their ML journey. The challenges span from the technology adoption to the teams and how they collaborate. Being successful with your ML journey will require time, effort, and practice. Expect it to be more than just a technology change. It will require changing and improving the way you collaborate and use technology. Make your team autonomous and prepare it to adapt to changes, enable a fail-fast culture, invest in technology, and always keep an eye on the business outcome.
We have also discussed some of the important attributes of an E2E ML platform. We will talk about this topic in-depth in the later parts of this book.
In the next chapter, we will introduce an emerging concept in ML projects, ML operations (MLOps). Through this, the industry is trying to bring the benefits of software engineering practices to ML projects. Let's dig in.
Further reading
If you want to learn more about the challenges in machine learning, you might be interested in the following articles as well.
- Hidden Technical Debt in Machine Learning, Sculley et al., 2015: https://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf
- Data Cascades in High-Stakes AI, Sambasivan et al., 2021: https://storage.googleapis.com/pub-tools-public-publication-data/pdf/0d556e45afc54afeb2eb6b51a9bc1827b9961ff4.pdf


