


















In this opening chapter, we will discover what OpenRefine is made for, why you should use it, and how. After a short introduction, we will go through seven fundamental recipes that will give you a foretaste of the power of OpenRefine:
Recipe 1 – installing OpenRefine
Recipe 2 – creating a new project
Recipe 3 – exploring your data
Recipe 4 – manipulating columns
Recipe 5 – using the project history
Recipe 6 – exporting a project
Recipe 7 – going for more memory
Although every recipe can be read independently from the others, we recommend that readers who are new to OpenRefine stick to the original order, at least for the first few recipes, since they provide crucial information about its general workings. More advanced users who already have an OpenRefine installation running can pick our tricks in any order they like.
Let's face a hard fact: your data are messy. All data are messy. Errors will always creep into large datasets no matter how much care you have put into creating them, especially when their creation has involved several persons and/or has been spread over a long timespan. Whether your data are born-digital or have been digitized, whether they are stored in a spreadsheet or in a database, something will always go awry somewhere in your dataset.
Acknowledging this messiness is the first essential step towards a sensible approach to data quality, which mainly involves data profiling and cleaning.
Data profiling is defined by Olson (Data Quality: The Accuracy Dimension, Jack E. Olson, Morgan Kaufman, 2003) as "the use of analytical techniques to discover the true structure, content, and quality of data". In other words, it is a way to get an assessment of the current state of your data and information about errors that they contain.
Data cleaning is the process that tries to correct those errors in a semi-automated way by removing blanks and duplicates, filtering and faceting rows, clustering and transforming values, splitting multi-valued cells, and so on.
Whereas custom scripts were formerly needed to perform data profiling and cleaning tasks, often separately, the advent of Interactive Data Transformation tools (IDTs) now allows for quick and inexpensive operations on large amounts of data inside a single integrated interface, even by domain professionals lacking in-depth technical skills.
OpenRefine is such an IDT; a tool for visualizing and manipulating data. It looks like a traditional, Excel-like spreadsheet software, but it works rather like a database, that is, with columns and fields rather than individual cells. This means that OpenRefine is not well suited for encoding new rows of data, but is extremely powerful when it comes to exploring, cleaning, and linking data.
The recipes gathered in this first chapter will help you to get acquainted with OpenRefine by reviewing its main functionalities, from import/export to data exploration and from history usage to memory management.
In this recipe, you will learn where to look in order to download the latest release of OpenRefine and how to get it running on your favorite operating system.
First things first: start by downloading OpenRefine from http://openrefine.org/. OpenRefine was previously known as Freebase Gridworks, then as Google Refine for a few years. Since October 2012, the project has been taken over by the community, which makes OpenRefine really open. OpenRefine 2.6 is the first version carrying the new branding. If you are interested in the development version, you can also check https://github.com/OpenRefine.
OpenRefine is based on the Java environment, which makes it platform-independent. Just make sure that you have an up-to-date version of Java running on your machine (available from http://java.com/download) and follow the following instructions, depending on your operating system:
It should be noted that, by default, OpenRefine will allocate only 1 GB of RAM to Java. While this is sufficient to handle small datasets, it soon becomes restrictive when dealing with larger collections of data. In Recipe 7 – going for more memory, we will detail how to allow OpenRefine to allocate more memory, an operation that also differs from one OS to the other.
In this recipe, you will learn how to get data into OpenRefine, whether by creating a new project and loading a dataset, opening an existing project from a previous session, or importing someone else's project.
If you successfully installed OpenRefine and launched it as explained in Recipe 1 – installing OpenRefine, you will notice that OpenRefine opens in your default browser. However, it is important to realize that the application is run locally: you do not need an Internet connection to use OpenRefine, except if you want to reconcile your data with external sources through the use of extensions (see Appendix, Regular Expressions and GREL for such advanced uses). Be also reassured that your sensitive data will not be stored online or shared with anyone. In practice, OpenRefine uses the port 3333 of your local machine, which means that it will be available through the URL http://localhost:3333/ or http://127.0.0.1:3333/.
Here is the start screen you will be looking at when you first open OpenRefine:
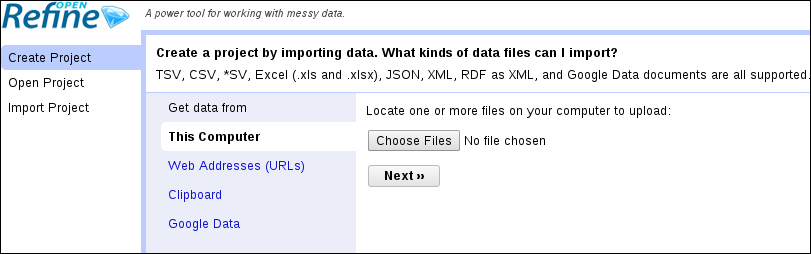
On the left, three tabs are available:
Create Project: This option loads a dataset into OpenRefine. This is what you will want when you use OpenRefine for the first time. There are various supported formats, as shown in the preceding screenshot. You can import data in different ways:
This Computer: Select a file stored on your local machine
Web Addresses (URLs): Import data directly from an online source*
Clipboard: Copy-paste your data into a text field
Google Data: Enable access to a Google Spreadsheet or Fusion Table*
*Internet connection required
Open Project: This option helps you go back to an existing project created during a former session. The next time you start OpenRefine, it will show a list of existing projects and propose you to continue working on a dataset that you have been using previously.
Import Project: With this option, we can directly import an existing OpenRefine project archive. This allows you to open a project that someone else has exported, including the history of all transformations already performed on the data since the project was created.
Here are some of the file formats supported by OpenRefine:
Comma-Separated Values (CSV), Tab-Separated Values (TSV), and other *SV
MS Excel documents (both .XLS and .XLSX) and Open Document Format (ODF) spreadsheets (.ODS), although the latter is not explicitly mentioned
JavaScript Object Notation (JSON)
XML and Resource Description Framework (RDF) as XML
Line-based formats (logs)
If you need other formats, you can add them by way of OpenRefine extensions.
Project creation with OpenRefine is straightforward and consists of three simple steps: selecting your file, previewing the import, and validating to let OpenRefine create your project. Let's create a new project by clicking on the Choose Files button from the This Computer tab, selecting your dataset (refer to the following information box), then clicking on Next.
Note
Although we encourage you to experiment with OpenRefine on your own dataset, it may be useful for you to be able to reproduce the examples used throughout this book. In order to facilitate this, all recipes are performed on the dataset from the Powerhouse Museum in Sydney, freely available from your account at http://www.packtpub.com (use the file chapter1.tsv). Feel free to download this file and load it into OpenRefine in order to follow the recipes more easily. Files are also present for the remaining chapters in a similar format for download. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
On the next screen, you get an overview of your dataset as it will appear in OpenRefine. In the bottom-right corner, you can see the following parsing options as shown in the following screenshot:

By default, the first line will be parsed as column headers, which is a common practice and relevant in the case of the Powerhouse dataset. OpenRefine will also attempt a guess for each cell type in order to differentiate text strings from integers, dates, and URLs among others. This will prove useful later when sorting your data (if you choose to keep the cells in plain text format, 10 will come before 2, for instance).
Another option demanding attention is the Quotation marks are used to enclose cells containing column separators checkbox. If you leave it selected, be sure to verify that the cell values are indeed enclosed in quotes in the original file. Otherwise, deselect this box to ensure that the quotation marks are not misinterpreted by OpenRefine. In the case of the Powerhouse collection, quotes are used inside cells to indicate object titles and inscriptions, for instance, so they have no syntactic meaning: we need to deselect the checkbox before going further. The other options may come in handy in some cases; try to select and deselect them in order to see how they affect your data. Also, be sure to select the right encoding to avoid special characters to being mixed up. When everything seems right, click on Create Project to load your data into OpenRefine.
In this recipe, you will get to know your data by scanning the different zones giving access to the total number of rows/records, the various display options, the column headers and menus, and the actual cell contents.
Once your dataset has been loaded, you will access the main interface of OpenRefine as shown in the following screenshot:

Four zones are seen on this screen; let's go through them from top to bottom, numbered as 1 to 4 in the preceding screenshot:
Total number of rows: If you did not forget to specify that quotation marks are to be ignored (see Recipe 2 – creating a new project), you should see a total of 75814 rows from the Powerhouse file. When data are filtered on a given criterion, this bar will display something like 123 matching rows (75814 total).
Display options: Try to alternate between rows and records by clicking on either word. True, not much will change, except that you may now read 75814 records in zone 1. The number of rows is always equal to the number of records in a new project, but they will evolve independently from now on. This zone will also let you choose whether to display 5, 10, 25, or 50 rows/records on a page, and it also provides the right way to navigate from page to page.
Column headers and menus: You will find here the first row that was parsed as column headers when the project was created. In the Powerhouse dataset, the columns read Record ID, Object Title, Registration Number, and so on (if you deselected the Parse next 1 line as column headers option box, you will see Column 1, Column 2, and so on instead). The leftmost column is always called All and is divided in three subcolumns containing stars (to mark good records, for instance), flags (to mark bad records, for instance), and IDs. Starred and flagged rows can easily be faceted, as we will see in Chapter 2, Analyzing and Fixing Data. Every column also has a menu (see the following screenshot) that can be accessed by clicking on the small dropdown to the left of the column header.
Cell contents: This option shows the main area displaying the actual values of the cells.

Before starting to profile and clean your data, it is important to get to know them well and to be at ease with OpenRefine: have a look at each column (using the horizontal scrollbar) to verify that the column headers have been parsed correctly, that the cell types were rightly guessed, and so on. Change the number of rows displayed per page to 50 and go through a few pages to check that the values are consistent (ideally, you should already have done so during preview before creating your project). When you feel that you are sufficiently familiar with the interface, you can consider moving along to the next recipe.
In this recipe, you will learn how the columns in OpenRefine can be collapsed and expanded again, moved around in any direction, or renamed and removed at leisure.
Columns are an essential part of OpenRefine: they contain thousands of values of the same nature and can be manipulated in a number of ways.
By default, all columns are expanded in OpenRefine, which can be cumbersome if there are many in the project. If you want to temporarily hide one or more columns to facilitate the work on the others, click on the dropdown in any column to show the menu and select View. Four options are available to you:
Collapse this column
Collapse all other columns
Collapse columns to left
Collapse columns to right
Here is a screenshot of the Powerhouse dataset after navigating to View | Collapse all other columns on the column Categories. To expand a column again, just click on it. To expand all of them and go back to the initial view, see the Moving columns around section in this recipe.

In some cases, it might be useful to change the order of the columns from the original file, for instance, to bring together columns that need to be compared. To achieve this, enter the menu of the chosen column and click on Edit column. Again, four options are available at the bottom of the submenu:
Move column to beginning
Move column to end
Move column to left
Move column to right
If you want to reorder the columns completely, use the first column called All. This column allows you to perform operations on several columns at the same time. The View option offers a quick way to collapse or expand all columns, while Edit columns | Re-order / remove columns... is an efficient way to rearrange columns by dragging them around or suppressing them by dropping them on the right, as shown in the following screenshot:

Under the same Edit column menu item, you also have the possibility to:
Rename this column
Remove this column
You could use renaming to suppress the unnecessary dot at the end of the Description column header, for instance. Removing a column is clearly more radical than simply collapsing it, but this can nevertheless be reversed, as you will learn by reading Recipe 5 – using the project history.
In this recipe, you will learn how you can go back in time at any point in the project's life and how to navigate through the history even if your project has been closed and opened again.
A very useful feature of OpenRefine is its handling of the history of all modifications that affected the data since the creation of the project. In practice, this means that you should never be afraid to try out things: do feel free at all times to fiddle with your data and to apply any transformation that crosses your mind, since everything can be undone in case you realize that it was a mistake (even if months have passed since the change was made).
To access the project history, click on the Undo / Redo tab in the top-left of the screen, just next to the Facet / Filter one, as shown in the following screenshot:

In order to turn back the clock, click on the last step that you want to be maintained. For instance, to cancel the removal of the column Provenance (Production) and all subsequent steps, click on 2. Rename column Description. to Description. Step 2 will be highlighted, and steps 3 to 5 will be grayed out. This means that the renaming will be kept, but not the next three steps. To cancel all changes and recover the data as they were before any transformation was made, click on 0. Create project. To undo the cancellation (redo), click on the step up to which you want to restore the history: for instance, click on 4. Reorder rows to apply steps 3 and 4 again, while maintaining the suppression of step 5 (rows removing).
Be cautious, however, that going back and doing something else will erase all subsequent steps. For instance, if you go back from step 5 to step 2 and then choose to move the column Description on the left, step 3 will now read 3. Move column description to position 1 and the gray steps in the preceding screenshot will disappear for good: you cannot have two conflicting histories recorded at the same time. Be sure to experiment with this in order to avoid nasty surprises in the future.
It is important to notice that only the operations actually affecting data are listed in the project history. Visual aids such as switching between the rows and records view, displaying less or more records on a page, or collapsing and expanding columns again, are not really transformations and are therefore not saved. A consequence is that they will be lost from one session to the other: when you come back to a project that was previously closed, all columns will be expanded again, whereas renamed and removed columns will still be the way you left them last time, along with every other operation stored in the project history. In Chapter 2, Analyzing and Fixing Data, we will see that this is also true for other types of operations: while cell and column transformations are registered in the history, filters and facets are not.
Note that operation history can also be extracted in JSON format by clicking on the Extract... button just under Undo / Redo. This will allow you to select the steps you want to extract (note that only reusable operations can be extracted, which excludes operations performed on specific cells), which will then be converted into JSON automatically and can then be copy-pasted. Steps 1 and 2 from the preceding screenshot would be expressed as:
[
{
"op": "core/column-move",
"description": "Move column Registration Number to position 1",
"columnName": "Registration Number",
"index": 1
},
{
"op": "core/column-rename",
"description": "Rename column Description. to Description",
"oldColumnName": "Description.",
"newColumnName": "Description"
}
]Tip
Downloading the example files
You can download the example files for all Packt books you have purchased from your account at http://www.packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
In the preceding code, op stands for operation, description actually describes what the operation does, and other variables are parameters passed to the operation (function). Steps that were previously saved as JSON in a text file can subsequently be reapplied to the same or another project by clicking on the Apply... button and pasting the extracted JSON history in the text area. Finally, in case you have performed several hundreds of operations and are at a loss to find some specific step, you can use the Filter field to restrict the history to the steps matching a text string. A filter on remove, for instance (or even on rem), would limit the displayed history to steps 3 and 5.
In this recipe, you will explore the various ways to save your modified data in order to reuse them in other contexts, including templating that allows for any custom export format to be used.
Although you may already have moved, renamed, or even removed columns, none of these modifications have been saved to your original dataset (that is, the chapter1.tsv file from Recipe 1 – installing OpenRefine has been left untouched). In fact, unlike most spreadsheet softwares that directly record changes into the files opened with them, OpenRefine always works in memory on an internal copy of the data. While this is an extra safety catch, it also means that any modified data needs to be exported before they are shared with others or injected in another application. The Export menu in the top-right of the screen allows you to do just that:

Most options propose to convert the data back into the file formats that were used during importation, such as CSV and TSV, Excel and Open Document, and different flavors of RDF. Let's have a closer look at other choices though:
Export project: This option allows you to export a zipped OpenRefine project in its internal format that can be shared with other people and imported on other machines or simply used for backup purposes.
HTML table: This option comes in handy if you want to publish your cleaned data online.
Triple loader and MQLWrite: This option has advanced options that require you to align the data to pre-existent schemas through the Freebase extension (there is more about that in Appendix, Regular Expressions and GREL).
Custom tabular exporter and templating: Maybe most interesting to you, OpenRefine lets you have a tight control on how your data are effectively exported by selecting and ordering columns, omitting blank rows and choosing the precise format of dates and reconciliation results (see Appendix, Regular Expressions and GREL again), and so on, as you can see in the next screenshot:

Templating...: For even more control, you can use your own personal template by typing the desired format once, which will then be applied to all cells. In the following code,
cells["Record ID"].value, for instance, corresponds to the actual value of each cell in the Record ID column which is then transformed into JSON, but could just as easily be formatted otherwise as shown in the following code snippet:{ "Record ID" : {{jsonize(cells["Record ID"].value)}}, "Object Title" : {{jsonize(cells["Object Title"].value)}}, "Registration Number" : {{jsonize(cells["Registration Number"].value)}}, "Description. " : {{jsonize(cells["Description. "].value)}}, "Marks" : {{jsonize(cells["Marks"].value)}}, "Production Date" : {{jsonize(cells["Production Date"].value)}}, }
In this last recipe, you will learn how to allocate more memory to the application in order to deal with larger datasets.
For large datasets, you might find that OpenRefine is performing slowly or shows you OutOfMemory errors. This is a sign that you should allocate more memory to the OpenRefine process. Unfortunately, this is a bit more complicated than the other things we have done so far, as it involves a bit of low-level fiddling. But don't worry: we'll guide you through it. The steps are different for each platform. A word of caution: the maximum amount of memory you can assign depends on the amount of RAM in your machine and whether you are using the 32 bit or 64 bit version of Java. When in doubt, try to increase the amount of memory gradually (for instance, in steps of 1024 MB) and check the result first.
On Windows, you will have to edit the openrefine.l4j.ini file in OpenRefine's main folder. Find the line that starts with -Xmx (which is Java speak for "maximum heap size"), which will show the default allocated memory: 1024M (meaning 1024 MB or 1 GB). Increase this as you see fit, for instance to 2048 M. The new settings will be in effect the next time you start OpenRefine.
The instructions for Mac are a bit more complicated, as this operating system hides the configuration files from sight. After closing OpenRefine, hold control and click on its icon, selecting Show package contents from the pop-up menu. Then, open the info.plist file from the Contents folder. You should now see a list of OpenRefine settings. Navigate to the Java settings and edit the value of VMOptions (these are the properties of the Java Virtual Machine). Look for the part that starts with -Xmx and change its default value of 1024 M to the desired amount of memory, for instance, -Xmx2048M.
This might come in as a surprise, but increasing allocated memory is easiest in Linux. Instead of starting OpenRefine with ./refine as you usually would do, just type in ./refine -m 2048M, where 2048 is the desired amount of memory in MB. To make the change permanent, you can create an alias in the hidden .bashrc file located in your home folder by adding the following line at the end of the file:
alias refine='cd path_to_refine ; ./refine -m 2048M'
Here, path_to_refine is the relative path from your home folder to the OpenRefine folder. Then, the next time you start OpenRefine with ./refine, it will be allocated 2 GB by default.
In this chapter, you have got to know OpenRefine, your new best friend for data profiling, cleaning, transformation, and many other things that you are still to discover. You now have an OpenRefine installation running and you know how to import your data into it by creating a new project and how to export them again after you are done. The mechanisms of rows and columns do not have any secrets for you any longer, and you understand how to navigate in the project history. You have also mastered memory allocation, which allows you to work on larger datasets.
Although it is always important to first have a good overview of what is in your dataset before dirtying your hands, you may now be getting impatient to perform actual changes on your data. If so, you are ready for Chapter 2, Analyzing and Fixing Data, which will move on to teach you the ins and outs of all the basic operations needed to analyze and fix your data.


