


















 Download code from GitHub
Download code from GitHub
Data Mining and Getting Started with Python Tools
In a sense, data mining is a necessary and predictable response to the dawn of the information age. Indeed, every piece of the modern global economy relies more each year on information and an immense in-stream of data. The path from information pool to actionable insights has many steps. Data mining is typically defined as the pattern and/or trend discovery phase in the pipeline.
This book is a quick-start guide for data mining and will include utilitarian descriptions of the most important and widely used methods, including the mainstays among data professionals such as k-means clustering, random forest prediction, and principal component dimensionality reduction. Along the way, I will give you tips I've learned and introduce helpful scripting tools to make your life easier. Not only will I introduce the tools, but I will clearly describe what makes them so helpful and why you should take the time to learn them.
The first half of the book will cover the nuts and bolts of data collection and preparation. The second half will be more conceptual and will introduce the topics of transformation, clustering, and prediction. The conceptual discussions start in the middle of Chapter 4, Cleaning and Readying Data for Analysis, and are written solely as a conversation between myself and the reader. These conversations are ported mostly from the many adhoc training sessions I've done over the years on Intel office marker boards. The last chapter of the book will be on the deployment of these models. This topic is the natural next step for new practitioners and I will provide an introduction and references for when you think you are ready to take the next steps.
The following topics will be covered in this chapter:
- Descriptive, predictive, and prescriptive analytics
- What will and will not be covered in this book
- Setting up Python environments for data mining
- Installing the Anaconda distribution and Conda package manager
- Launching the Spyder IDE
- Launching a Jupyter Notebook
- Installing a high performance Python distribution
- Recommended libraries and how to install
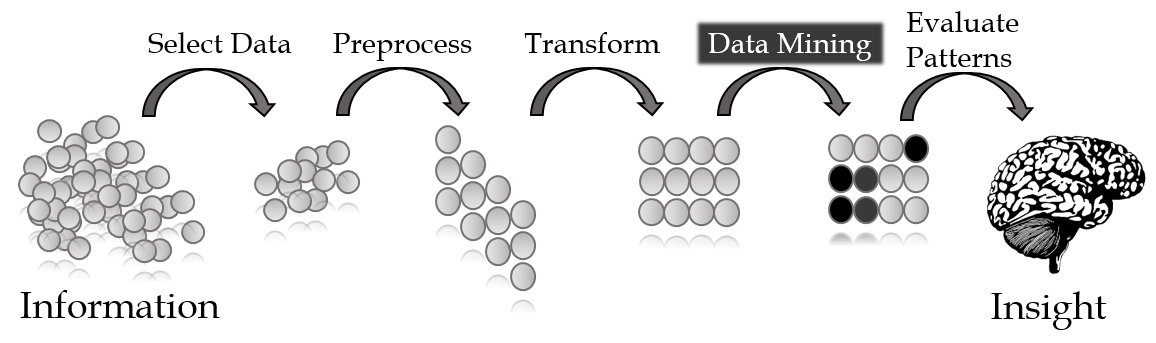
Descriptive, predictive, and prescriptive analytics
Practitioners in the field of data analysis usually break down their work into three genres of analytics, given as follows:
- Descriptive: Descriptive is the oldest field of analytics study and involves digging deep into the data to hunt down and extract previously unidentified trends, groupings, or other patterns. This was the predominant type of analytics done by the pioneering groups in the field of data mining, and for a number of years the two terms were considered more or less to mean the same thing. However, predictive analytics blossomed in the early 2000s along with the burgeoning field of machine learning, and the many of the techniques that came out of the data mining community proved useful for prediction.
- Predictive: Predictive analytics, as the name suggests, focuses on predicting future outcomes and relies on the assumption that past descriptions necessarily lead to future behavior. This concept demonstrates the strong and unavoidable connection between descriptive and predictive analytics. In recent years, industry has naturally taken the next logical step of using prediction to feed into prescriptive solutions.
- Prescriptive: Prescriptive analytics relies heavily on customer goals, seeks personalized scoring systems for predictions, and is still a relatively immature field of study and practice. This is accomplished by modeling various response strategies and scoring against the personalized score system.
Please see the following table for a summary:
|
Type of analytics |
Problem statement addressed |
| Descriptive | What happened? |
| Predictive | What will happen next? |
| Prescriptive | How should we respond? |
What will and will not be covered in this book
A quick and dirty description of data mining I hear in the field can be paraphrased as: "Descriptive and predictive analytics with a focus on previously hidden relationships or trends". As such, this book will cover these topics and skip the predictive analytics that focus on automation of obvious prediction, along with the entire field of prescriptive analytics entirely. This text is meant to be a quick start guide, so even the relevant fields of study will only be skimmed over and summarized. Please see the Recommended reading for further explanation section for inquiring minds that want to delve deeper into some of the subjects covered in this book.
Preprocessing and data transformation are typically considered to be outside of the data mining category. One of the goals of this book is to provide full working data mining examples, and basic preprocessing is required to do this right. So, this book will cover those topics, before delving in to the more traditional mining strategies.
Recommended readings for further explanation
These books are good for more in-depth discussions and as an introduction to important and relevant topics. I recommend that you start with these if you want to become an expert:
- Data mining in practice:
Data Mining: Practical Machine Learning Tools and Techniques, 4th Edition by Ian H. Witten (author), Eibe Frank (author), Mark A. Hall (author), Christopher J. Pal
- Data mining advanced discussion and mathematical foundation:
Data Mining and Analysis: Fundamental Concepts and Algorithms, 1st Edition by Mohammed J. Zaki (author), Wagner Meira Jr (author)
- Computer science taught with Python:
Python Programming: An Introduction to Computer Science, 3rd Edition by John Zelle (author)
- Python machine learning and analytics:
Python Machine Learning: Machine Learning and Deep Learning with Python, scikit-learn, and TensorFlow, 2nd Edition Paperback—September 20, 2017 by Sebastian Raschka (author), Vahid Mirjalili (author)
Advanced Machine Learning with Python Paperback—July 28, 2016 by John Hearty
Setting up Python environments for data mining
A computing setup conducive to advanced data mining requires a comfortable development environment and working libraries for data management, analytics, plotting, and deployment. The popular bundled Python distribution from Anaconda is a perfect fit for the job. It is targeted at scientists and engineers, and includes all the required packages to get started. Conda itself is a package manager for maintaining working Python environments and, of course, is included in the bundle. The package manager will allow you to install/remove combinations of libraries into segregated Python environments, all the while reconciling any version dependencies between the distinct libraries.
It includes an integrated development environment called The Scientific Python Development Environment (Spyder) and a ready-to-use implementation of Jupyter Notebook interface. Both of these development environments use the interactive Python console called IPython. IPython gives you a live console for scripting. You can run a single line of code, check results, then run another line of code in same console in an interactive fashion. A few trial-and-error sessions with IPython will demonstrate very clearly why these Python tools are so beloved by practitioners working in a rapid prototyping environment.
Installing the Anaconda distribution and Conda package manager
These tools from Anaconda are available on both Windows and Linux systems. See the following install instructions.
Installing on Linux
To install the distribution, follow these steps given as follows:
- First, download the latest installer build from https://www.anaconda.com/download/#linux.
- Then, in the Linux Terminal, pass this bash command:
$ bash Anaconda-latest-Linux-x86_64.sh
- Follow the prompts in the terminal and it will begin installing. Once done, you will be asked if you want to allow Conda to be auto-initialized with a .bashrc entry. I recommend choosing N and activating it manually when needed, just in case you decide to have multiple versions of Conda on your system. In this case, you can launch the Conda prompt by using the following command:
$ source /{anaconda3_dir}/bin/activate
This is will source the Conda activate shell script and call it to activate the base environment, which is the default Anaconda Python bundle. Adding new environments will be discussed in the following section on how to install specific libraries. At this point, passing the Python command will open an interactive shell where you can execute Python code line-by-line, as shown in the following code snippet:
(base) $ Python
Python 3.7.0 (default, Jun 28 2018, 13:15:42)
[GCC 7.2.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import numpy
>>> numpy.random.random(10)
array([0.48489815, 0.80944492, 0.89740441, 0.93031125, 0.71774534,
0.63817451, 0.93231809, 0.75820457, 0.17550135, 0.62126858])
Alternatively, you can execute the code in a stored Python script by using the following command:
(base) $ Python script.py
Installing on Windows
To install on Windows, follow the steps given as follows:
- First, download the executable from https://conda.io/docs/user-guide/install/windows.html
- Then, launch the Anaconda prompt that can be found in a program search from the Windows Start menu
Anaconda prompt is a Windows command prompt with all the environment variables set to point to Anaconda. That's it; you are ready to use your base Python environment.
Installing on macOS
To install on macOS, follow the steps given as follows:
- First, download the graphical installer from the Anaconda distribution site https://www.anaconda.com/distribution/
- Launch the package and follow the on-screen prompts, which should set up everything you need automatically
Launching the Spyder IDE
Spyder can be started by passing spyder into the Anaconda prompt as follows:
(base) $ spyder
As mentioned earlier, Spyder uses the IPython interactive console. So, you can pass code line-by-line directly into the console. See the following screenshot for two lines of Python code passed one at a time:

Alternatively, you can edit a script in the editor and execute by pressing the green play button at the top of the IDE. This causes the script to be dumped into the IPython console, then run line-by-line:
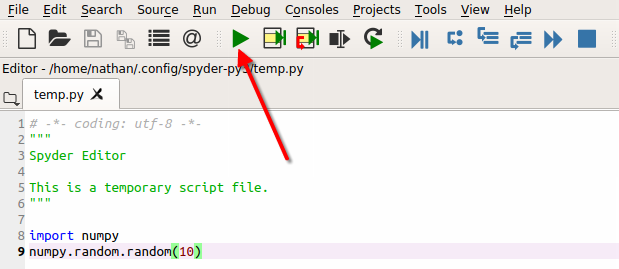
The interactive IPython console also can display images and plots inline in the same console window. This is yet another feature that is very convenient for interactive data mining and rapid prototyping of analytics models:

Launching a Jupyter Notebook
The Jupyter project spun out of the popular IPython Notebook work of the early 2000s. These notebooks provide a visual interface with sequential text and code cells. This allows you to add some text to describe a solution, then follow it with code examples. The Jupyter Notebook also use the IPython console (similar to Spyder), so you have an interactive code interpretor that can plot images inline. Launching the notebook from the Anaconda prompt is simple:
(base) $ jupyter notebook
The Jupyter project maintains a few basic notebooks. Let's look at a screenshot from one of them, as follows (it can be found at http://nbviewer.jupyter.org/github/temporaer/tutorial_ml_gkbionics):

The concept is self-explanatory if we look at a few examples. The following are recommendations for some relevant and helpful Jupyter Notebooks on data mining and analytics from around the web:
https://github.com/rasbt/python-machine-learning-book/blob/master/code/ch01/ch01.ipynb
http://nbviewer.jupyter.org/github/amplab/datascience-sp14/blob/master/hw2/HW2.ipynb
https://github.com/TomAugspurger/PyDataSeattle/blob/master/notebooks/1.%20Basics.ipynb
Installing high-performance Python distribution
Intel Corp has built a bundle of Python libraries with accelerations for High-Performance Computing (HPC) on CPUs. The vast majority of the accelerations come with no code changes, because they are snuck in under the hood. All the concepts and libraries introduced in the rest of the book will run faster in the HPC Intel Python environment. Luckily, Intel has a Conda version of their distribution, so you can add it as a new Conda environment via the following few command lines in the Anaconda prompt:
(base) $ Conda create -n idp -c channel intelpython3_full Python=3
(base) $ Conda activate idp
Full disclosure: I work for Intel, so I won't focus too much on this HPC distribution. I will merely let the performance numbers speak for themselves. See the following graph for raw speedup numbers (optimized versus stock) when using unchanged Scikit-learn code on CPU:

Recommended libraries and how to install
Its easy to add or remove libraries from the Anaconda prompt. Once you have an the preferred environment activated, the simple Conda install command will search the Anaconda cloud repo for a matching package, and will begin download if it exists. Conda will warn if there are version dependencies with your other libraries. Always pay attention to these warnings, so that you know if any other library versions are affected. If, at any time, you need a reminder of what is in your environment, use the Conda list command to check package names and versions.
Let's look at some example commands:
- Create a new environment called my_env with Python version 3 using the following command:
(base) $ Conda create -n my_env Python=3
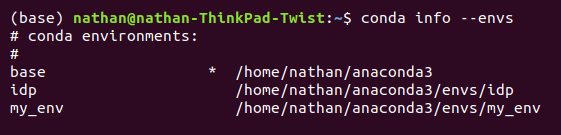
- Check whether my_env was created successfully by using the following command:
(base) $ Conda info --envs
You will see the following screen on the execution of the preceding command:
- Activate a new environment by using the following command:
(base) $ Conda activate my_env
- Install the numpy math library by using the following command:
(my_env) $ Conda install numpy
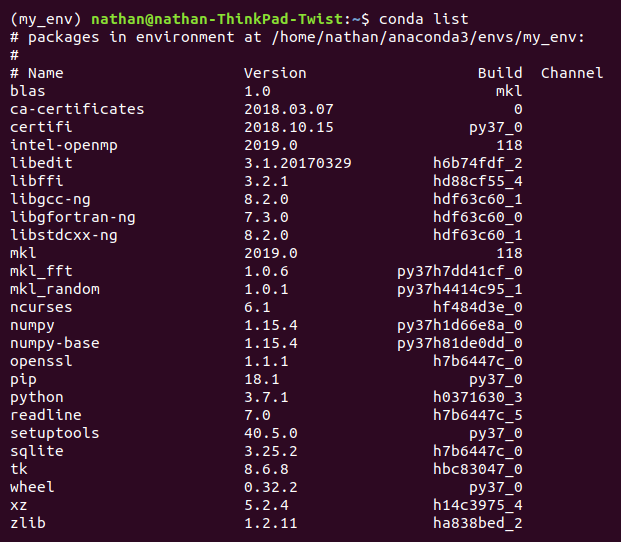
- Use Conda list as follows, to check whether a new library was installed or not and all other libraries and versions in my_env:
(my_env) $ Conda list
You will see the following screen on the execution of the preceding command:
Recommended libraries
If you choose to manage a smaller environment than the full bundle from Anaconda, I recommend the following essential libraries for data mining. They will be used throughout this book:
- numpy: The fundamental math library for Python. Brings with it the numpy array data structure.
- scipy: Provides science and engineering routines built on the base of the numpy array. This library also has some good statistical functions.
- pandas: Offers relational data tables for storing, labeling, viewing, and manipulating data. You will never look at an array of numbers in the same way for the rest of your career after you've gotten comfortable with pandas and its popular data structure, called a dataframe.
- matplotlib: Python's core visualization library with line and scatter plots, bar and pie charts, histograms and spectrograms, and so on.
- seaborn: As statistical visualization library. Built on top of matplotlib and much easier to use. You can build complicated visual representations with, in many cases, a single line of code. This library takes pandas dataframes as input.
- statsmodels: Library focused on statistics functions and statistical testing. For example, it has a .summary() function that returns helpful summary stats and information about a model you've applied.
- scikit-learn: Python's workhorse machine learning library. It is easy to use and is maintained by an army of developers. The best part is the documentation on http:\\scikit-learn.org . It is so extensive that one could learn the field of machine learning just by reading though the entirety of it.
Summary
This chapter introduced the contents of the book and covered getting started with your software environment. It also covered how to get high-speed Python and popular libraries such as pandas, scikit-learn, and seaborn. After reading this chapter and setting your environment, you should be ready to follow along with the demonstrations throughout the rest of the book.


