


















 Download code from GitHub
Download code from GitHub
This chapter intends to provide and describe the big-picture around Spark, which includes Spark architecture. You will be taken from the higher-level details of the framework to installing Spark and writing your very first program on Spark.
We'll cover the following core topics in this chapter. If you are already familiar with these topics please feel free to jump to the next chapter on Spark: Resilient Distributed Datasets (RDDs):
Apache Spark architecture overview:
- Apache Spark deployment
- Installing Apache Spark
- Writing your first Spark program
- Submitting applications
Apache Spark is being an open source distributed data processing engine for clusters, which provides a unified programming model engine across different types data processing workloads and platforms.
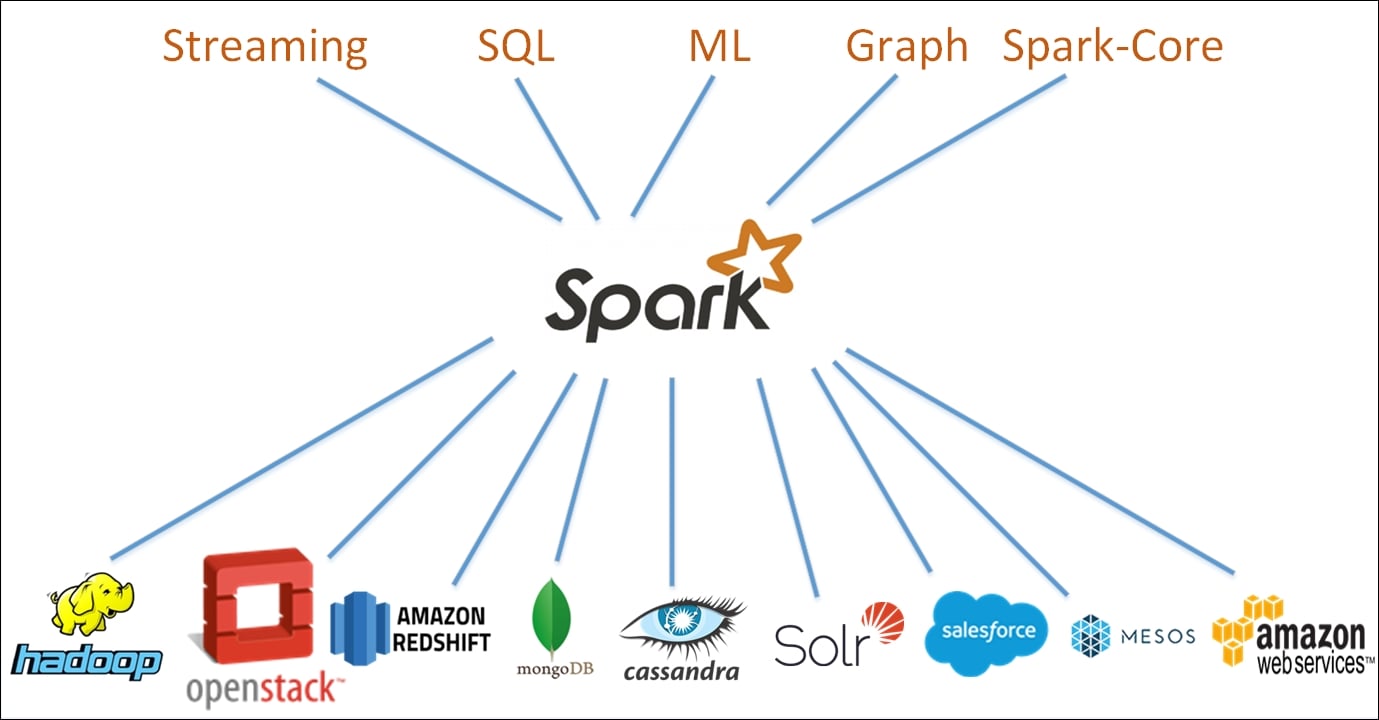
Figure 1.1: Apache Spark Unified Stack
At the core of the project is a set of APIs for Streaming, SQL, Machine Learning (ML), and Graph. Spark community supports the Spark project by providing connectors to various open source and proprietary data storage engines. Spark also has the ability to run on a variety of cluster managers like YARN and Mesos, in addition to the Standalone cluster manager which comes bundled with Spark for standalone installation. This is thus a marked difference from Hadoop eco-system where Hadoop provides a complete platform in terms of storage formats, compute engine, cluster manager, and so on. Spark has been designed with the single goal of being an optimized compute engine. This therefore allows you to run Spark on a variety of cluster managers including being run standalone, or being plugged into YARN and Mesos. Similarly, Spark does not have its own storage, but it can connect to a wide number of storage engines.
Currently Spark APIs are available in some of the most common languages including Scala, Java, Python, and R.
Let's start by going through various API's available in Spark.
At the heart of the Spark architecture is the core engine of Spark, commonly referred to as spark-core, which forms the foundation of this powerful architecture. Spark-core provides services such as managing the memory pool, scheduling of tasks on the cluster (Spark works as a Massively Parallel Processing (MPP) system when deployed in cluster mode), recovering failed jobs, and providing support to work with a wide variety of storage systems such as HDFS, S3, and so on.
Tip
Spark-Core provides a full scheduling component for Standalone Scheduling: Code is available at: https://github.com/apache/spark/tree/master/core/src/main/scala/org/apache/spark/scheduler
Spark-Core abstracts the users of the APIs from lower-level technicalities of working on a cluster. Spark-Core also provides the RDD APIs which are the basis of other higher-level APIs, and are the core programming elements on Spark. We'll talk about RDD, DataFrame and Dataset APIs later in this book.
Spark SQL is one of the most popular modules of Spark designed for structured and semi-structured data processing. Spark SQL allows users to query structured data inside Spark programs using SQL or the DataFrame and the Dataset API, which is usable in Java, Scala, Python, and R. Because of the fact that the DataFrame API provides a uniform way to access a variety of data sources, including Hive datasets, Avro, Parquet, ORC, JSON, and JDBC, users should be able to connect to any data source the same way, and join across these multiple sources together. The usage of Hive meta store by Spark SQL gives the user full compatibility with existing Hive data, queries, and UDFs. Users can seamlessly run their current Hive workload without modification on Spark.
Spark SQL can also be accessed through spark-sql shell, and existing business tools can connect via standard JDBC and ODBC interfaces.
More than 50% of users consider Spark Streaming to be the most important component of Apache Spark. Spark Streaming is a module of Spark that enables processing of data arriving in passive or live streams of data. Passive streams can be from static files that you choose to stream to your Spark cluster. This can include all sorts of data ranging from web server logs, social-media activity (following a particular Twitter hashtag), sensor data from your car/phone/home, and so on. Spark-streaming provides a bunch of APIs that help you to create streaming applications in a way similar to how you would create a batch job, with minor tweaks.
As of Spark 2.0, the philosophy behind Spark Streaming is not to reason about streaming and building data application as in the case of a traditional data source. This means the data from sources is continuously appended to the existing tables, and all the operations are run on the new window. A single API lets the users create batch or streaming applications, with the only difference being that a table in batch applications is finite, while the table for a streaming job is considered to be infinite.
MLlib is Machine Learning Library for Spark, if you remember from the preface, iterative algorithms are one of the key drivers behind the creation of Spark, and most machine learning algorithms perform iterative processing in one way or another.
Note
Machine learning is a type of artificial intelligence (AI) that provides computers with the ability to learn without being explicitly programmed. Machine learning focuses on the development of computer programs that can teach themselves to grow and change when exposed to new data.
Spark MLlib allows developers to use Spark API and build machine learning algorithms by tapping into a number of data sources including HDFS, HBase, Cassandra, and so on. Spark is super fast with iterative computing and it performs 100 times better than MapReduce. Spark MLlib contains a number of algorithms and utilities including, but not limited to, logistic regression, Support Vector Machine (SVM), classification and regression trees, random forest and gradient-boosted trees, recommendation via ALS, clustering via K-Means, Principal Component Analysis (PCA), and many others.
GraphX is an API designed to manipulate graphs. The graphs can range from a graph of web pages linked to each other via hyperlinks to a social network graph on Twitter connected by followers or retweets, or a Facebook friends list.
Graph theory is a study of graphs, which are mathematical structures used to model pairwise relations between objects. A graph is made up of vertices (nodes/points), which are connected by edges (arcs/lines). | ||
| --Wikipedia.org | ||
Spark provides a built-in library for graph manipulation, which therefore allows the developers to seamlessly work with both graphs and collections by combining ETL, discovery analysis, and iterative graph manipulation in a single workflow. The ability to combine transformations, machine learning, and graph computation in a single system at high speed makes Spark one of the most flexible and powerful frameworks out there. The ability of Spark to retain the speed of computation with the standard features of fault-tolerance makes it especially handy for big data problems. Spark GraphX has a number of built-in graph algorithms including PageRank, Connected components, Label propagation, SVD++, and Triangle counter.
Apache Spark runs on both Windows and Unix-like systems (for example, Linux and Mac OS). If you are starting with Spark you can run it locally on a single machine. Spark requires Java 7+, Python 2.6+, and R 3.1+. If you would like to use Scala API (the language in which Spark was written), you need at least Scala version 2.10.x.
Spark can also run in a clustered mode, using which Spark can run both by itself, and on several existing cluster managers. You can deploy Spark on any of the following cluster managers, and the list is growing everyday due to active community support:
- Hadoop YARN
- Apache Mesos
- Standalone scheduler
- Yet Another Resource Negotiator (YARN) is one of the key features including a redesigned resource manager thus splitting out the scheduling and resource management capabilities from original Map Reduce in Hadoop .
- Apache Mesos is an open source cluster manager that was developed at the University of California, Berkeley. It provides efficient resource isolation and sharing across distributed applications, or frameworks.
As mentioned in the earlier pages, while Spark can be deployed on a cluster, you can also run it in local mode on a single machine.
In this chapter, we are going to download and install Apache Spark on a Linux machine and run it in local mode. Before we do anything we need to download Apache Spark from Apache's web page for the Spark project:
- Use your recommended browser to navigate to http://spark.apache.org/downloads.html.
- Choose a Spark release. You'll find all previous Spark releases listed here. We'll go with release 2.0.0 (at the time of writing, only the preview edition was available).
- You can download Spark source code, which can be built for several versions of Hadoop, or download it for a specific Hadoop version. In this case, we are going to download one that has been pre-built for Hadoop 2.7 or later.
You can also choose to download directly or from among a number of different Mirrors. For the purpose of our exercise we'll use direct download and download it to our preferred location.
The file that you have downloaded is a compressed TAR archive. You need to extract the archive.
Once unpacked, you will see a number of directories/files. Here's what you would typically see when you list the contents of the unpacked directory:
The
binfolder contains a number of executable shell scripts such aspypark,sparkR,spark-shell,spark-sql, andspark-submit. All of these executables are used to interact with Spark, and we will be using most if not all of these.If you see my particular download of spark you will find a folder called
yarn. The example below is a Spark that was built for Hadoop version 2.7 which comes with YARN as a cluster manager.
Figure 1.2: Spark folder contents
We'll start by running Spark shell, which is a very simple way to get started with Spark and learn the API. Spark shell is a Scala Read-Evaluate-Print-Loop (REPL), and one of the few REPLs available with Spark which also include Python and R.
You should change to the Spark download directory and run the Spark shell as follows: /bin/spark-shell

Figure 1.3: Starting Spark shell
We now have Spark running in standalone mode. We'll discuss the details of the deployment architecture a bit later in this chapter, but now let's kick start some basic Spark programming to appreciate the power and simplicity of the Spark framework.
As mentioned before, you can use Spark with Python, Scala, Java, and R. We have different executable shell scripts available in the /spark/bin directory and so far, we have just looked at Spark shell, which can be used to explore data using Scala. The following executables are available in the spark/bin directory. We'll use most of these during the course of this book:
beelinePySparkrun-examplespark-classsparkRspark-shellspark-sqlspark-submit
Whatever shell you use, based on your past experience or aptitude, you have to deal with one abstract that is your handle to the data available on the spark cluster, be it local or spread over thousands of machines. The abstraction we are referring to here is called Resilient Distributed Datasets (RDD), and is a fundamental unit of your data and computation in Spark. As the name indicates, among others, they have two key features:
- They are resilient: If the data in memory is lost, an RDD can be recreated
- They are distributed: You can Java objects or Python objects that are distributed across clusters
Chapter 2, Transformations and Actions with Spark RDDs, will walk through the intricacies of RDD while we will also discuss other higher-level APIs built on top of RDDs, such as Dataframes and machine learning pipelines.
Let's quickly demonstrate how you can explore a file on your local file system using Spark. Earlier in Figure 1.2, when we were exploring spark folder contents we saw a file called README.md, which contains an overview of Spark, the link to online documentation, and other assets available to the developers and analysts. We are going to read that file, and convert it into an RDD.
To enter Scala shell, please submit the following command:
./bin/spark-shellUsing the Scala shell, run the following code:
val textFile = sc.textFile("README.md") # Create an RDD called tTextFileAt the prompt you immediately get a confirmation on the type of variable created:

Figure 1.4: Creating a simple RDD
If you want to see the type of operations available on the RDD, at Command Prompt write the variable name textFile in this case, and press the Tab
key. You'll see the following list of operations/actions available:
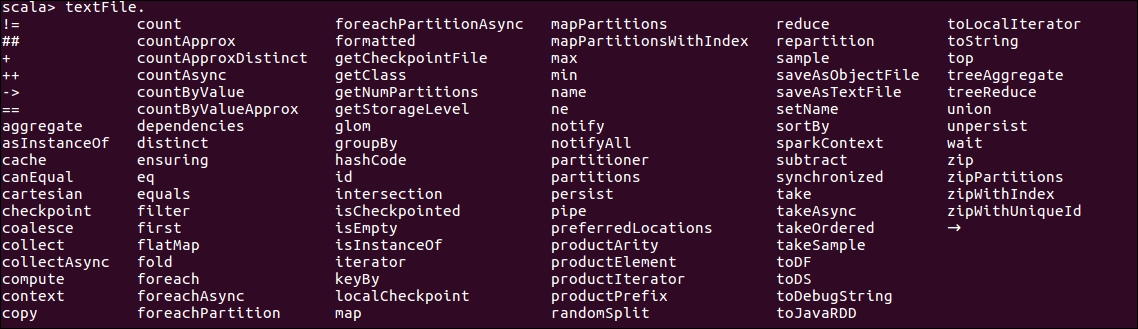
Figure 1.5: Operations on String RDDs
Since our objective is to do some basic exploratory analysis, we will look at some of the basic actions on this RDD.
Note
RDD's can have actions or transformations called upon them, but the result of each is different. Transformations result in new RDD's being created while actions result in the RDD to be evaluated, and return the values back to the client.
Let's look at the top seven lines from this RDD:
textFile.take(7) # Returns the top 7 lines from the file as an Array of StringsThe result of this looks something like the following:

Figure 1.6: First seven lines from the file
Alternatively, let's look at the total number of lines in the file, another action available as a list of actions on a string RDD. Please note that each line from the file is considered a separate item in the RDD:
textFile.count() # Returns the total number of items

Figure 1.7: Counting RDD elements
We've looked at some actions, so now let's try to look at some transformations available as a part of string RDD operations. As mentioned earlier, transformations are operations that return another RDD as a result.
Let's try to filter the data file, and find out the data lines with the keyword Apache:
val linesWithApache = textFile.filter(line => line.contains("Apache"))This transformation will return another string RDD.
You can also chain multiple transformations and actions together. For example, the following will filter the text file on the lines that contain the word Apache, and then return the number of such lines in the resultant RDD:
textFile.filter(line => line.contains("Apache")).count()
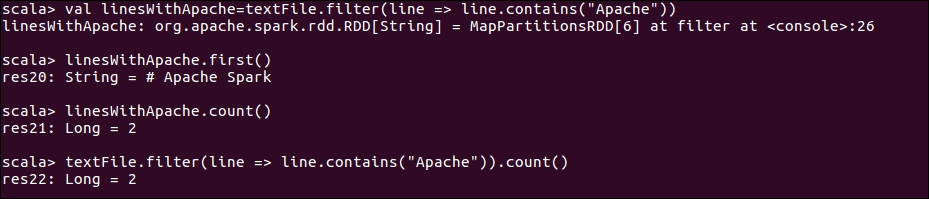
Figure 1.8: Transformations and actions
You can monitor the jobs that are running on this cluster from Spark UI, which is running by default at port 4040.
If you navigate your browser to http://localhost:4040, you should see the following Spark driver program UI:
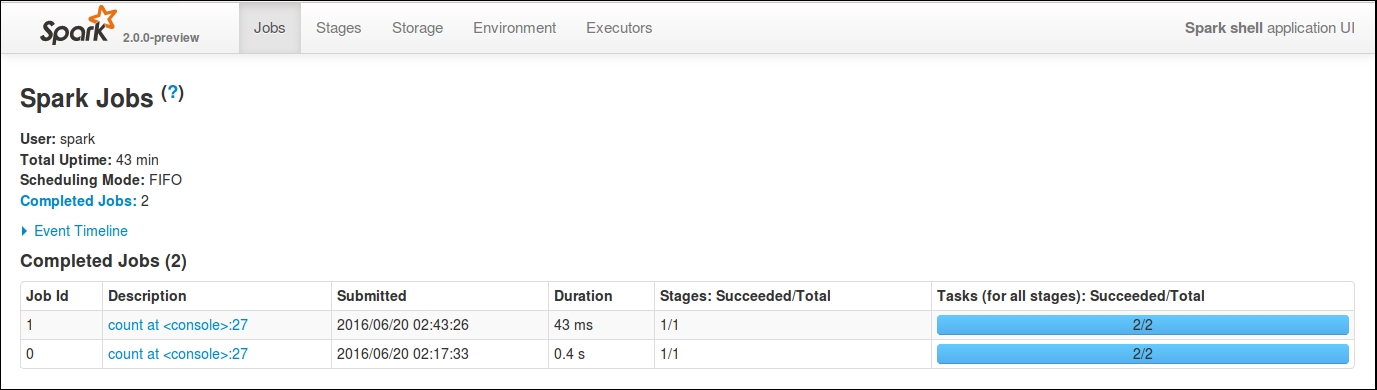
Figure 1.9: Spark driver program UI
Depending on how many jobs you have run, you will see a list of jobs based on their status. The UI gives you an overview of the type of job, its submission date/time, the amount of time it took, and the number of stages that it had to pass through. If you want to look at the details of the job, simply click the description of the job, which will take you to another web page that details all the completed stages. You might want to look at individual stages of the job. If you click through the individual stage, you can get detailed metrics about your job.
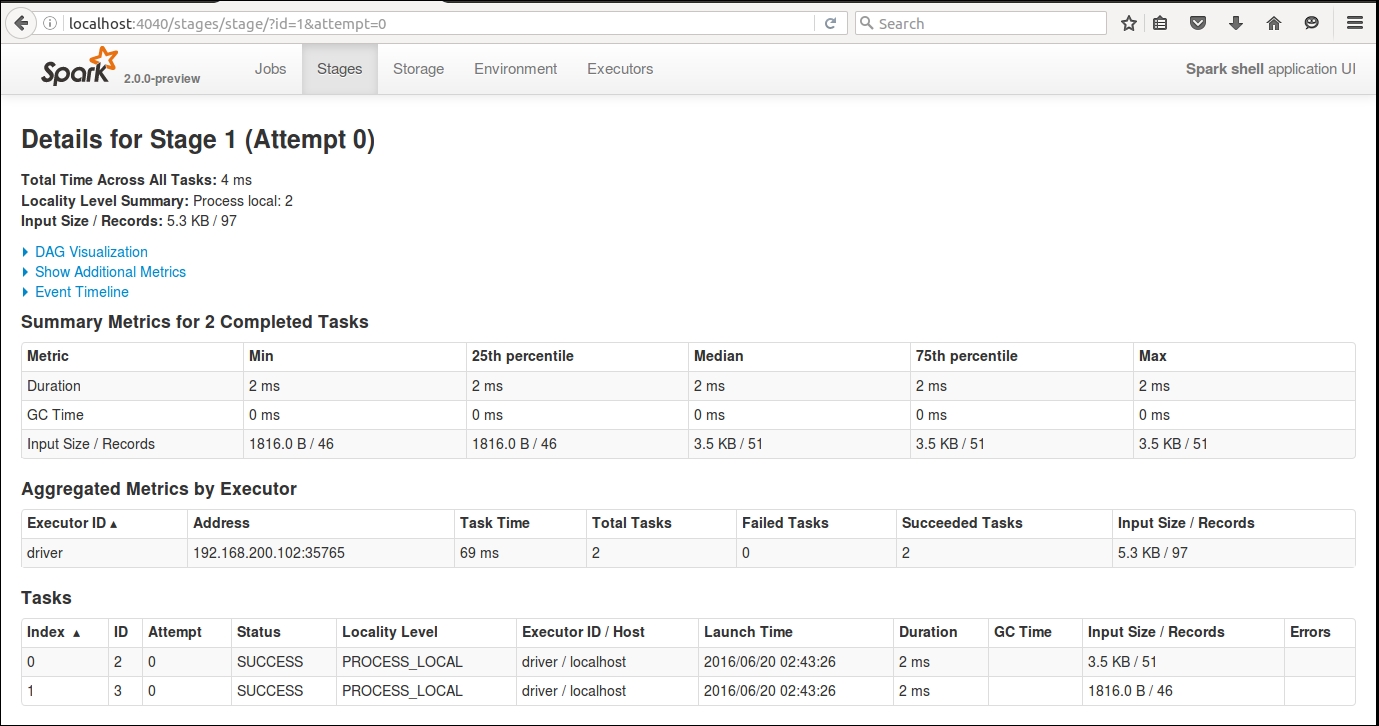
Figure 1.10: Summary metrics for the job
We'll go through DAG Visualization, Event Timeline, and other aspects of the UI in a lot more detail in later chapters, but the objective of showing this to you was to highlight how you can monitor your jobs during and after execution.
Before we go any further with examples, let's replay the same examples from a Python Shell for Python programmers.
For those of you who are more comfortable with Python, rather than Scala, we will walk through the previous examples from the Python shell too.
To enter Python shell, please submit the following command:
./bin/pysparkYou'll see an output similar to the following:
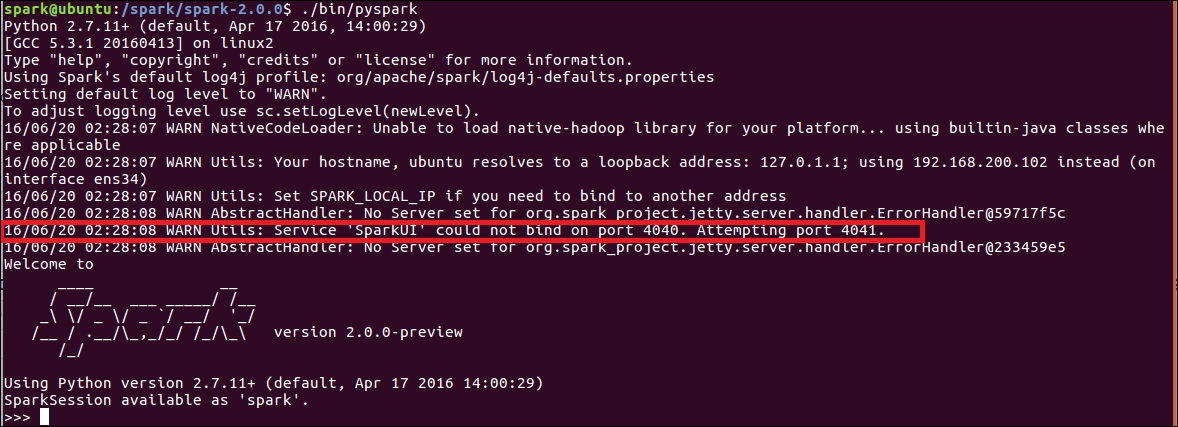
Figure 1.11: Spark Python shell
If you look closely at the output, you will see that the framework tried to start the Spark UI at port 4040, but was unable to do so. It has instead started the UI at port 4041. Can you guess why? The reason is because we already have port 4040 occupied, and Spark will continue trying ports after port 4040 until it finds one available to bind the UI to.
Let's do some basic data manipulation using Python at the Python shell. Once again we will read the README.md file:
textFile = sc.textFile("README.md") //Create and RDD called textFile by reading the contents of README.md fileLet's read the top seven lines from the file:
textFile.take(7)Let's look at the total number of lines in the file:
textFile.count()You'll see output similar to the following:

Figure 1.12: Exploratory data analysis with Python
As we demonstrated with Scala shell, we can also filter data using Python by applying transformations and chain transformations with actions.
Use the following code to apply transformation on the dataset. Remember, a transformation results in another RDD.
Here's a code to apply transformation, which is filtering the input dataset, and identifying lines that contain the word Apache:
linesWithApache = textFile.filter(lambda line: "Apache" in line) //Find lines with Apache
Once we have obtained the filtered RDD, we can apply an action to it:
linesWithApache.count() //Count number of itemsLet's chain the transformation and action together:
textFile.filter(lambda line: "Apache" in line).count() //Chain transformation and action together

Figure 1.13: Chaining transformations and actions in Python
If you are unfamiliar with lambda functions in Python, please don't worry about it at this moment. The objective of this demonstration is to show you how easy it is to explore data with Spark. We'll cover this in much more detail in later chapters.
If you want to have a look at the driver program UI, you will find that the summary metrics are pretty much similar to what we saw when the execution was done using Scala shell.
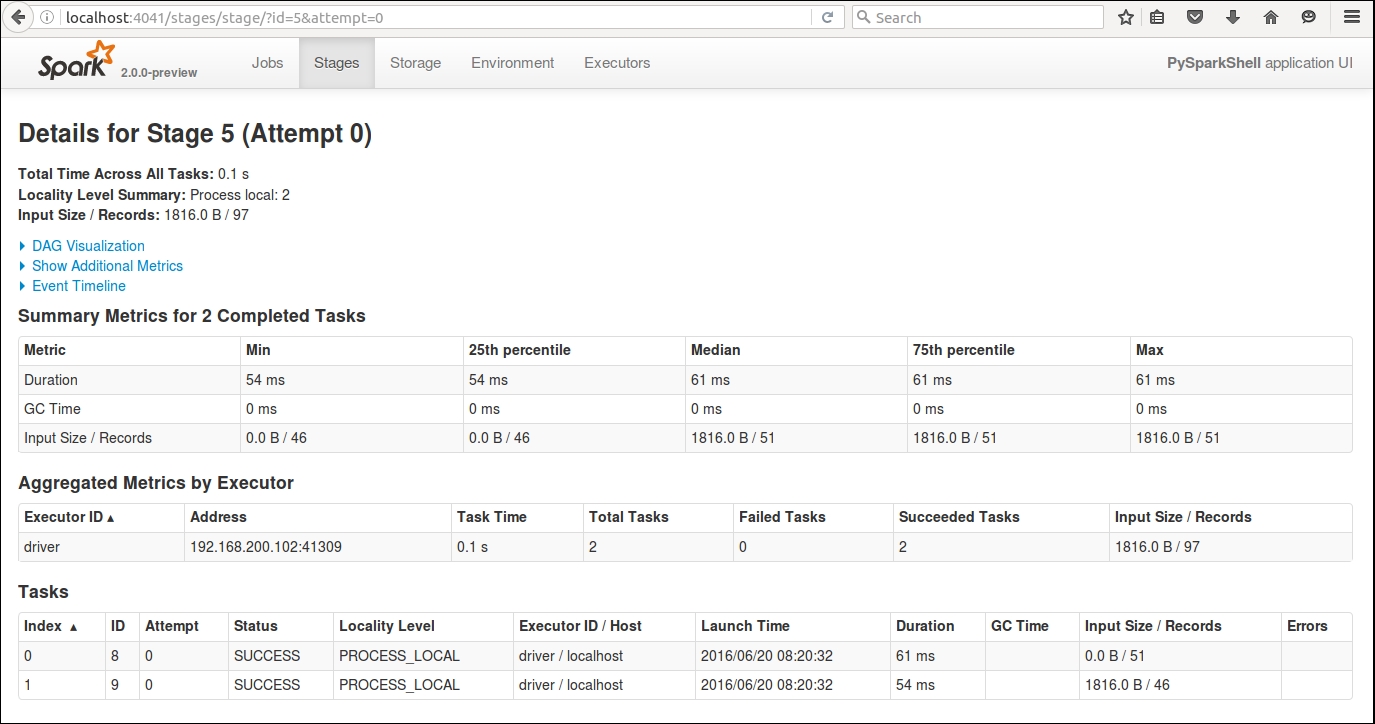
Figure 1.14: Spark UI demonstrating summary metrics.
We have now gone through some basic Spark programs, so it might be worth understanding a bit more about the Spark architecture. In the next section, we will dig deeper into Spark architecture before moving onto the next chapter where we will have a lot more code examples explaining the various concepts around RDDs.
Let's have a look at Apache Spark architecture, including a high level overview and a brief description of some of the key software components.
At the high level, Apache Spark application architecture consists of the following key software components and it is important to understand each one of them to get to grips with the intricacies of the framework:
- Driver program
- Master node
- Worker node
- Executor
- Tasks
- SparkContext
- SQL context
- Spark session
Here's an overview of how some of these software components fit together within the overall architecture:

Figure 1.15: Apache Spark application architecture - Standalone mode
Driver program is the main program of your Spark application. The machine where the Spark application process (the one that creates SparkContext and Spark Session) is running is called the Driver node, and the process is called the Driver process. The driver program communicates with the Cluster Manager to distribute tasks to the executors.
A cluster manager as the name indicates manages a cluster, and as discussed earlier Spark has the ability to work with a multitude of cluster managers including YARN, Mesos and a Standalone cluster manager. A standalone cluster manager consists of two long running daemons, one on the master node, and one on each of the worker nodes. We'll talk more about the cluster managers and deployment models in Chapter 8, Operating in Clustered Mode.
If you are familiar with Hadoop, a Worker Node is something similar to a slave node. Worker machines are the machines where the actual work is happening in terms of execution inside Spark executors. This process reports the available resources on the node to the master node. Typically each node in a Spark cluster except the master runs a worker process. We normally start one spark worker daemon per worker node, which then starts and monitors executors for the applications.
The master allocates the resources and uses the workers running across the cluster to create Executors for the driver. The driver can then use these executors to run its tasks. Executors are only launched when a job execution starts on a worker node. Each application has its own executor processes, which can stay up for the duration of the application and run tasks in multiple threads. This also leads to the side effect of application isolation and non-sharing of data between multiple applications. Executors are responsible for running tasks and keeping the data in memory or disk storage across them.
A task is a unit of work that will be sent to one executor. Specifically speaking, it is a command sent from the driver program to an executor by serializing your Function object. The executor deserializes the command (as it is part of your JAR that has already been loaded) and executes it on a partition.
A partition is a logical chunk of data distributed across a Spark cluster. In most cases Spark would be reading data out of a distributed storage, and would partition the data in order to parallelize the processing across the cluster. For example, if you are reading data from HDFS, a partition would be created for each HDFS partition. Partitions are important because Spark will run one task for each partition. This therefore implies that the number of partitions are important. Spark therefore attempts to set the number of partitions automatically unless you specify the number of partitions manually e.g. sc.parallelize (data,numPartitions).
SparkContext is the entry point of the Spark session. It is your connection to the Spark cluster and can be used to create RDDs, accumulators, and broadcast variables on that cluster. It is preferable to have one SparkContext active per JVM, and hence you should call stop() on the active SparkContext before you create a new one. You might have noticed previously that in the local mode, whenever we start a Python or Scala shell we have a SparkContext object created automatically and the variable sc refers to the SparkContext object. We did not need to create the SparkContext, but instead started using it to create RDDs from text files.
As discussed previously, Apache Spark currently supports three Cluster managers:
- Standalone cluster manager
- ApacheMesos
- Hadoop YARN
We'll look at setting these up in much more detail in Chapter 8, Operating in Clustered Mode, which talks about the operation in a clustered mode.
Until now we have used Spark for exploratory analysis, using Scala and Python shells. Spark can also be used in standalone applications that can run in Java, Scala, Python, or R. As we saw earlier, Spark shell and PySpark provide you with a SparkContext. However, when you are using an application, you need to initialize your own SparkContext. Once you have a SparkContext reference, the remaining API remains exactly the same as for interactive query analysis. After all, it's the same object, just a different context in which it is running.
The exact method of using Spark with your application differs based on your preference of language. All Spark artifacts are hosted in Maven central. You can add a Maven dependency with the following coordinates:
groupId: org.apache.spark artifactId: spark_core_2.10 version: 1.6.1
You can use Maven to build the project or alternatively use Scale/Eclipse IDE to add a Maven dependency to your project.
Note
Apache Maven is a build automation tool used primarily for Java projects. The word maven means "accumulator of knowledge" in Yiddish. Maven addresses the two core aspects of building software: first, it describes how the software is built and second, it describes its dependencies.
You can configure your IDE's to work with Spark. While many of the Spark developers use SBT or Maven on the command line, the most common IDE being used is IntelliJ IDEA. Community edition is free, and after that you can install JetBrains Scala Plugin. You can find detailed instructions on setting up either IntelliJIDEA or Eclipse to build Spark at http://bit.ly/28RDPFy.
The spark submit script in Spark's bin directory, being the most commonly used method to submit Spark applications to a Spark cluster, can be used to launch applications on all supported cluster types. You will need to package all dependent projects with your application to enable Spark to distribute that across the cluster. You would need to create an assembly JAR (aka uber/fat JAR) file containing all of your code and relevant dependencies.
A spark application with its dependencies can be launched using the bin/spark-submit script. This script takes care of setting up the classpath and its dependencies, and it supports all the cluster-managers and deploy modes supported by Spark.

Figure 1.16: Spark submission template
For Python applications:
- Instead of
<application-jar>, simply pass in your.pyfile. - Add Python
.zip,.egg, and.pyfiles to the search path with -.pyfiles.
- Client mode: This is commonly used when your application is located near to your cluster. In this mode, the driver application is launched as a part of the spark-submit process, which acts as a client to the cluster. The input and output of the application is passed on to the console. The mode is suitable when your gateway machine is physically collocated with your worker machines, and is used in applications such as Spark shell that involve REPL. This is the default mode.
- Cluster mode: This is useful when your application is submitted from a machine far from the worker machines (for example, locally on your laptop) to minimize network latency between the drivers and the executors. Currently only YARN supports cluster mode for Python applications. The following table shows that the combination of cluster managers, deployment managers, and usage that are not supported in Spark 2.0.0:
|
Cluster Manager |
Deployment Mode |
Application Type |
Support |
|
MESOS |
Cluster |
R |
Not Supported |
|
Standalone |
Cluster |
Python |
Not Supported |
|
Standalone |
Cluster |
R |
Not Supported |
|
Local |
Cluster |
- |
Incompatible |
|
- |
Cluster |
Spark-Shell |
Not applicable |
|
- |
Cluster |
Sql-Shell |
Not Applicable |
|
- |
Cluster |
Thrift Server |
Not Applicable |
Spark comes with packaged examples for Java, Python, Scala, and R. We'll demonstrate how you can run a program provided in the examples directory.
As we only have a local installation, we'll run the Spark PI example locally on 4 cores. The examples are available at the Apache Spark GitHub page http://bit.ly/28S1hDY. We've taken an excerpt out of the example to explain how SparkContext is initialized:
val conf = new SparkConf().setAppName("Spark Pi")
val spark = new SparkContext(conf)
The example comes packaged with Spark binaries. The code can be downloaded from GitHub too. Looking closely at the code you will realize that we instantiate our own SparkContext object from a SparkConf object. The application name Spark PI will appear in the Spark UI as a running application during the execution, and will help you track the status of your job. Remember, this is in stark contrast to the spark-shell where a SparkContext is automatically instantiated and passed as a reference.
Let's run this example with Spark submit script:

The log of the script spans over multiple pages, so we will skip over the intermediate manipulation step and go to the part where the output is printed. Remember in this case we are running Spark Pi, which prints out a value of Pi. Here's the second part of the log:

Figure 1.17: Running Spark Pi example
At the moment we have seen an example in Scala. If we see the example for this in Python, you will realize that we will just need to pass in the Python source code. We do not have to pass in any JAR files, as we are not referencing any other code. Similar to the Scala example, we have to instantiate the SparkContext directly, which is unlike how PySpark shell automatically provides you with a reference to the context object:
sc = SparkContext(appName="PythonPi")Running the Spark Pi example is a bit different to the Scala example:

Similar to the PySpark example, the log of the SparkPi program in spark-shell spans multiple pages. We'll just move directly to the part where the value of Pi is printed in the log:

Figure 1.18: Running Spark Pi Python example
We have tested pre-compiled programs but, as discussed earlier in this chapter, you can create your own programs and use sbt or Maven to package the application together and run using spark-submit script. In the later chapters in this book, we will use both the REPL environments and spark-submit for various code examples. For a complete code example, we'll build a Recommendation system in Chapter 9, Building a Recommendation System, and predict customer churn in a telco environment in Chapter 10, Customer Churn Prediction. Both of these examples (though fictional) will help you understand the overall life cycle of a machine learning application.
- https://en.wikipedia.org/wiki/Apache_Mesos
https://aws.amazon.com/ec2/- http://spark.apache.org/docs/2.0.0-preview/quick-start.html
- http://spark.apache.org/docs/2.0.0-preview/cluster-overview.html
- http://spark.apache.org/docs/2.0.0-preview/submitting-applications.html
- https://en.wikipedia.org/wiki/Apache_Maven
- http://cdn2.hubspot.net/hubfs/438089/DataBricks_Surveys_-_Content/2016_Spark_Survey/2016_Spark_Infographic.pdf
In this chapter, we have gone through a Spark architecture overview, written our first Spark program, looked at the software components of Spark, and ran a Spark application. This provides a solid foundation to move to the next chapter where we will discuss Spark RDDs, which is one of the most important constructs of Apache Spark.

