


















In this chapter, we will cover the following recipes:
Setting up standalone Hadoop v2 on your local machine
Writing a WordCount MapReduce application, bundling it, and running it using Hadoop local mode
Adding a combiner step to the WordCount MapReduce program
Setting up HDFS
Setting up Hadoop YARN in a distributed cluster environment using Hadoop v2
Setting up Hadoop ecosystem in a distributed cluster environment using a Hadoop distribution
HDFS command-line file operations
Running the WordCount program in a distributed cluster environment
Benchmarking HDFS using DFSIO
Benchmarking Hadoop MapReduce using TeraSort
We are living in the era of big data, where exponential growth of phenomena such as web, social networking, smartphones, and so on are producing petabytes of data on a daily basis. Gaining insights from analyzing these very large amounts of data has become a must-have competitive advantage for many industries. However, the size and the possibly unstructured nature of these data sources make it impossible to use traditional solutions such as relational databases to store and analyze these datasets.
Storage, processing, and analyzing petabytes of data in a meaningful and timely manner require many compute nodes with thousands of disks and thousands of processors together with the ability to efficiently communicate massive amounts of data among them. Such a scale makes failures such as disk failures, compute node failures, network failures, and so on a common occurrence making fault tolerance a very important aspect of such systems. Other common challenges that arise include the significant cost of resources, handling communication latencies, handling heterogeneous compute resources, synchronization across nodes, and load balancing. As you can infer, developing and maintaining distributed parallel applications to process massive amounts of data while handling all these issues is not an easy task. This is where Apache Hadoop comes to our rescue.
Note
Google is one of the first organizations to face the problem of processing massive amounts of data. Google built a framework for large-scale data processing borrowing the map and reduce paradigms from the functional programming world and named it as MapReduce. At the foundation of Google, MapReduce was the Google File System, which is a high throughput parallel filesystem that enables the reliable storage of massive amounts of data using commodity computers. Seminal research publications that introduced Google MapReduce and Google File System concepts can be found at http://research.google.com/archive/mapreduce.html and http://research.google.com/archive/gfs.html.
Apache Hadoop MapReduce is the most widely known and widely used open source implementation of the Google MapReduce paradigm. Apache Hadoop Distributed File System (HDFS) provides an open source implementation of the Google File Systems concept.
Apache Hadoop MapReduce, HDFS, and YARN provide a scalable, fault-tolerant, distributed platform for storage and processing of very large datasets across clusters of commodity computers. Unlike in traditional High Performance Computing (HPC) clusters, Hadoop uses the same set of compute nodes for data storage as well as to perform the computations, allowing Hadoop to improve the performance of large scale computations by collocating computations with the storage. Also, the hardware cost of a Hadoop cluster is orders of magnitude cheaper than HPC clusters and database appliances due to the usage of commodity hardware and commodity interconnects. Together Hadoop-based frameworks have become the de-facto standard for storing and processing big data.
HDFS is a block structured distributed filesystem that is designed to store petabytes of data reliably on compute clusters made out of commodity hardware. HDFS overlays on top of the existing filesystem of the compute nodes and stores files by breaking them into coarser grained blocks (for example, 128 MB). HDFS performs better with large files. HDFS distributes the data blocks of large files across to all the nodes of the cluster to facilitate the very high parallel aggregate read bandwidth when processing the data. HDFS also stores redundant copies of these data blocks in multiple nodes to ensure reliability and fault tolerance. Data processing frameworks such as MapReduce exploit these distributed sets of data blocks and the redundancy to maximize the data local processing of large datasets, where most of the data blocks would get processed locally in the same physical node as they are stored.
HDFS consists of NameNode and DataNode services providing the basis for the distributed filesystem. NameNode stores, manages, and serves the metadata of the filesystem. NameNode does not store any real data blocks. DataNode is a per node service that manages the actual data block storage in the DataNodes. When retrieving data, client applications first contact the NameNode to get the list of locations the requested data resides in and then contact the DataNodes directly to retrieve the actual data. The following diagram depicts a high-level overview of the structure of HDFS:

Hadoop v2 brings in several performance, scalability, and reliability improvements to HDFS. One of the most important among those is the High Availability (HA) support for the HDFS NameNode, which provides manual and automatic failover capabilities for the HDFS NameNode service. This solves the widely known NameNode single point of failure weakness of HDFS. Automatic NameNode high availability of Hadoop v2 uses Apache ZooKeeper for failure detection and for active NameNode election. Another important new feature is the support for HDFS federation. HDFS federation enables the usage of multiple independent HDFS namespaces in a single HDFS cluster. These namespaces would be managed by independent NameNodes, but share the DataNodes of the cluster to store the data. The HDFS federation feature improves the horizontal scalability of HDFS by allowing us to distribute the workload of NameNodes. Other important improvements of HDFS in Hadoop v2 include the support for HDFS snapshots, heterogeneous storage hierarchy support (Hadoop 2.3 or higher), in-memory data caching support (Hadoop 2.3 or higher), and many performance improvements.
Almost all the Hadoop ecosystem data processing technologies utilize HDFS as the primary data storage. HDFS can be considered as the most important component of the Hadoop ecosystem due to its central nature in the Hadoop architecture.
YARN (Yet Another Resource Negotiator) is the major new improvement introduced in Hadoop v2. YARN is a resource management system that allows multiple distributed processing frameworks to effectively share the compute resources of a Hadoop cluster and to utilize the data stored in HDFS. YARN is a central component in the Hadoop v2 ecosystem and provides a common platform for many different types of distributed applications.
The batch processing based MapReduce framework was the only natively supported data processing framework in Hadoop v1. While MapReduce works well for analyzing large amounts of data, MapReduce by itself is not sufficient enough to support the growing number of other distributed processing use cases such as real-time data computations, graph computations, iterative computations, and real-time data queries. The goal of YARN is to allow users to utilize multiple distributed application frameworks that provide such capabilities side by side sharing a single cluster and the HDFS filesystem. Some examples of the current YARN applications include the MapReduce framework, Tez high performance processing framework, Spark processing engine, and the Storm real-time stream processing framework. The following diagram depicts the high-level architecture of the YARN ecosystem:

The YARN ResourceManager process is the central resource scheduler that manages and allocates resources to the different applications (also known as jobs) submitted to the cluster. YARN NodeManager is a per node process that manages the resources of a single compute node. Scheduler component of the ResourceManager allocates resources in response to the resource requests made by the applications, taking into consideration the cluster capacity and the other scheduling policies that can be specified through the YARN policy plugin framework.
YARN has a concept called containers, which is the unit of resource allocation. Each allocated container has the rights to a certain amount of CPU and memory in a particular compute node. Applications can request resources from YARN by specifying the required number of containers and the CPU and memory required by each container.
ApplicationMaster is a per-application process that coordinates the computations for a single application. The first step of executing a YARN application is to deploy the ApplicationMaster. After an application is submitted by a YARN client, the ResourceManager allocates a container and deploys the ApplicationMaster for that application. Once deployed, the ApplicationMaster is responsible for requesting and negotiating the necessary resource containers from the ResourceManager. Once the resources are allocated by the ResourceManager, ApplicationMaster coordinates with the NodeManagers to launch and monitor the application containers in the allocated resources. The shifting of application coordination responsibilities to the ApplicationMaster reduces the burden on the ResourceManager and allows it to focus solely on managing the cluster resources. Also having separate ApplicationMasters for each submitted application improves the scalability of the cluster as opposed to having a single process bottleneck to coordinate all the application instances. The following diagram depicts the interactions between various YARN components, when a MapReduce application is submitted to the cluster:

While YARN supports many different distributed application execution frameworks, our focus in this book is mostly on traditional MapReduce and related technologies.
Hadoop MapReduce is a data processing framework that can be utilized to process massive amounts of data stored in HDFS. As we mentioned earlier, distributed processing of a massive amount of data in a reliable and efficient manner is not an easy task. Hadoop MapReduce aims to make it easy for users by providing a clean abstraction for programmers by providing automatic parallelization of the programs and by providing framework managed fault tolerance support.
MapReduce programming model consists of Map and Reduce functions. The Map function receives each record of the input data (lines of a file, rows of a database, and so on) as key-value pairs and outputs key-value pairs as the result. By design, each Map function invocation is independent of each other allowing the framework to use divide and conquer to execute the computation in parallel. This also allows duplicate executions or re-executions of the Map tasks in case of failures or load imbalances without affecting the results of the computation. Typically, Hadoop creates a single Map task instance for each HDFS data block of the input data. The number of Map function invocations inside a Map task instance is equal to the number of data records in the input data block of the particular Map task instance.
Hadoop MapReduce groups the output key-value records of all the Map tasks of a computation by the key and distributes them to the Reduce tasks. This distribution and transmission of data to the Reduce tasks is called the Shuffle phase of the MapReduce computation. Input data to each Reduce task would also be sorted and grouped by the key. The Reduce function gets invoked for each key and the group of values of that key (reduce <key, list_of_values>) in the sorted order of the keys. In a typical MapReduce program, users only have to implement the Map and Reduce functions and Hadoop takes care of scheduling and executing them in parallel. Hadoop will rerun any failed tasks and also provide measures to mitigate any unbalanced computations. Have a look at the following diagram for a better understanding of the MapReduce data and computational flows:

In Hadoop 1.x, the MapReduce (MR1) components consisted of the JobTracker process, which ran on a master node managing the cluster and coordinating the jobs, and TaskTrackers, which ran on each compute node launching and coordinating the tasks executing in that node. Neither of these processes exist in Hadoop 2.x MapReduce (MR2). In MR2, the job coordinating responsibility of JobTracker is handled by an ApplicationMaster that will get deployed on-demand through YARN. The cluster management and job scheduling responsibilities of JobTracker are handled in MR2 by the YARN ResourceManager. JobHistoryServer has taken over the responsibility of providing information about the completed MR2 jobs. YARN NodeManagers provide the functionality that is somewhat similar to MR1 TaskTrackers by managing resources and launching containers (which in the case of MapReduce 2 houses Map or Reduce tasks) in the compute nodes.
Hadoop v2 provides three installation choices:
Local mode: The local mode allows us to run MapReduce computation using just the unzipped Hadoop distribution. This nondistributed mode executes all parts of Hadoop MapReduce within a single Java process and uses the local filesystem as the storage. The local mode is very useful for testing/debugging the MapReduce applications locally.
Pseudo distributed mode: Using this mode, we can run Hadoop on a single machine emulating a distributed cluster. This mode runs the different services of Hadoop as different Java processes, but within a single machine. This mode is good to let you play and experiment with Hadoop.
Distributed mode: This is the real distributed mode that supports clusters that span from a few nodes to thousands of nodes. For production clusters, we recommend using one of the many packaged Hadoop distributions as opposed to installing Hadoop from scratch using the Hadoop release binaries, unless you have a specific use case that requires a vanilla Hadoop installation. Refer to the Setting up Hadoop ecosystem in a distributed cluster environment using a Hadoop distribution recipe for more information on Hadoop distributions.
Note
The example code files for this book are available on GitHub at https://github.com/thilg/hcb-v2. The chapter1 folder of the code repository contains the sample source code files for this chapter. You can also download all the files in the repository using the https://github.com/thilg/hcb-v2/archive/master.zip link.
The sample code for this book uses Gradle to automate the compiling and building of the projects. You can install Gradle by following the guide provided at http://www.gradle.org/docs/current/userguide/installation.html. Usually, you only have to download and extract the Gradle distribution from http://www.gradle.org/downloads and add the bin directory of the extracted Gradle distribution to your path variable.
All the sample code can be built by issuing the gradle build command in the main folder of the code repository.
Project files for Eclipse IDE can be generated by running the gradle eclipse command in the main folder of the code repository.
Project files for the IntelliJ IDEA IDE can be generated by running the gradle idea command in the main folder of the code repository.
This recipe describes how to set up Hadoop v2 on your local machine using the local mode. Local mode is a non-distributed mode that can be used for testing and debugging your Hadoop applications. When running a Hadoop application in local mode, all the required Hadoop components and your applications execute inside a single Java Virtual Machine (JVM) process.
Download and install JDK 1.6 or a higher version, preferably the Oracle JDK 1.7. Oracle JDK can be downloaded from http://www.oracle.com/technetwork/java/javase/downloads/index.html.
Now let's start the Hadoop v2 installation:
Download the most recent Hadoop v2 branch distribution (Hadoop 2.2.0 or later) from http://hadoop.apache.org/releases.html.
Unzip the Hadoop distribution using the following command. You will have to change the
x.x.in the filename to the actual release you have downloaded. From this point onward, we will call the unpacked Hadoop directory{HADOOP_HOME}:$ tar -zxvf hadoop-2.x.x.tar.gzNow, you can run Hadoop jobs through the
{HADOOP_HOME}/bin/hadoopcommand, and we will elaborate on that further in the next recipe.
Hadoop local mode does not start any servers but does all the work within a single JVM. When you submit a job to Hadoop in local mode, Hadoop starts a JVM to execute the job. The output and the behavior of the job is the same as a distributed Hadoop job, except for the fact that the job only uses the current node to run the tasks and the local filesystem is used for the data storage. In the next recipe, we will discover how to run a MapReduce program using the Hadoop local mode.
This recipe explains how to implement a simple MapReduce program to count the number of occurrences of words in a dataset. WordCount is famous as the HelloWorld equivalent for Hadoop MapReduce.
To run a MapReduce job, users should supply a map function, a reduce function, input data, and a location to store the output data. When executed, Hadoop carries out the following steps:
Hadoop uses the supplied InputFormat to break the input data into key-value pairs and invokes the
mapfunction for each key-value pair, providing the key-value pair as the input. When executed, themapfunction can output zero or more key-value pairs.Hadoop transmits the key-value pairs emitted from the Mappers to the Reducers (this step is called Shuffle). Hadoop then sorts these key-value pairs by the key and groups together the values belonging to the same key.
For each distinct key, Hadoop invokes the reduce function once while passing that particular key and list of values for that key as the input.
The
reducefunction may output zero or more key-value pairs, and Hadoop writes them to the output data location as the final result.
Select the source code for the first chapter from the source code repository for this book. Export the $HADOOP_HOME environment variable pointing to the root of the extracted Hadoop distribution.
Now let's write our first Hadoop MapReduce program:
The WordCount sample uses MapReduce to count the number of word occurrences within a set of input documents. The sample code is available in the
chapter1/Wordcount.javafile of the source folder of this chapter. The code has three parts—Mapper, Reducer, and the main program.The Mapper extends from the
org.apache.hadoop.mapreduce.Mapperinterface. Hadoop InputFormat provides each line in the input files as an input key-value pair to themapfunction. Themapfunction breaks each line into substrings using whitespace characters such as the separator, and for each token (word) emits(word,1)as the output.public void map(Object key, Text value, Context context) throws IOException, InterruptedException { // Split the input text value to words StringTokenizer itr = new StringTokenizer(value.toString()); // Iterate all the words in the input text value while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, new IntWritable(1)); } }Each
reducefunction invocation receives a key and all the values of that key as the input. Thereducefunction outputs the key and the number of occurrences of the key as the output.public void reduce(Text key, Iterable<IntWritable>values, Context context) throws IOException, InterruptedException { int sum = 0; // Sum all the occurrences of the word (key) for (IntWritableval : values) { sum += val.get(); } result.set(sum); context.write(key, result); }The
maindriver program configures the MapReduce job and submits it to the Hadoop YARN cluster:Configuration conf = new Configuration(); …… // Create a new job Job job = Job.getInstance(conf, "word count"); // Use the WordCount.class file to point to the job jar job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // Setting the input and output locations FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, newPath(otherArgs[1])); // Submit the job and wait for it's completion System.exit(job.waitForCompletion(true) ? 0 : 1);
Compile the sample using the Gradle build as mentioned in the introduction of this chapter by issuing the
gradle buildcommand from thechapter1folder of the sample code repository. Alternatively, you can also use the provided Apache Ant build file by issuing theant compilecommand.Run the WordCount sample using the following command. In this command,
chapter1.WordCountis the name of themainclass.wc-inputis the input data directory andwc-outputis the output path. Thewc-inputdirectory of the source repository contains a sample text file. Alternatively, you can copy any text file to thewc-inputdirectory.$ $HADOOP_HOME/bin/hadoop jar \ hcb-c1-samples.jar \ chapter1.WordCount wc-input wc-output
The output directory (
wc-output) will have a file namedpart-r-XXXXX, which will have the count of each word in the document. Congratulations! You have successfully run your first MapReduce program.$ cat wc-output/part*
In the preceding sample, MapReduce worked in the local mode without starting any servers and using the local filesystem as the storage system for inputs, outputs, and working data. The following diagram shows what happened in the WordCount program under the covers:
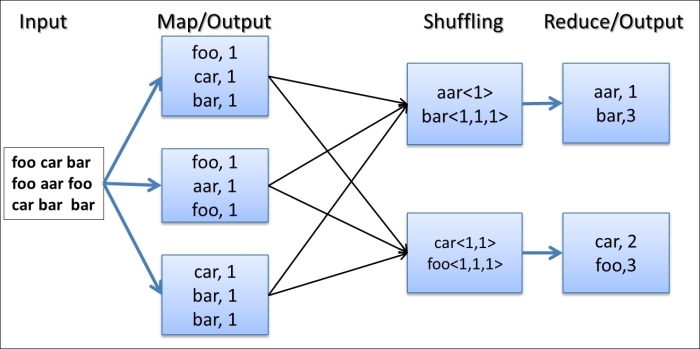
The WordCount MapReduce workflow works as follows:
Hadoop reads the input, breaks it using new line characters as the separator and then runs the
mapfunction passing each line as an argument with the line number as the key and the line contents as the value.The
mapfunction tokenizes the line, and for each token (word), emits a key-value pair(word,1).Hadoop collects all the
(word,1)pairs, sorts them by the word, groups all the values emitted against each unique key, and invokes thereducefunction once for each unique key passing the key and values for that key as an argument.The
reducefunction counts the number of occurrences of each word using the values and emits it as a key-value pair.Hadoop writes the final output to the output directory.
As an optional step, you can set up and run the WordCount application directly from your favorite Java Integrated Development Environment (IDE). Project files for Eclipse IDE and IntelliJ IDEA IDE can be generated by running gradle eclipse and gradle idea commands respectively in the main folder of the code repository.
For other IDEs, you'll have to add the JAR files in the following directories to the class-path of the IDE project you create for the sample code:
{HADOOP_HOME}/share/hadoop/common{HADOOP_HOME}/share/hadoop/common/lib{HADOOP_HOME}/share/hadoop/mapreduce{HADOOP_HOME}/share/hadoop/yarn{HADOOP_HOME}/share/hadoop/hdfs
Execute the chapter1.WordCount class by passing wc-input and wc-output as arguments. This will run the sample as before. Running MapReduce jobs from IDE in this manner is very useful for debugging your MapReduce jobs.
Although you ran the sample with Hadoop installed in your local machine, you can run it using the distributed Hadoop cluster setup with an HDFS-distributed filesystem. The Running the WordCount program in a distributed cluster environment recipe of this chapter will discuss how to run this sample in a distributed setup.
A single Map task may output many key-value pairs with the same key causing Hadoop to shuffle (move) all those values over the network to the Reduce tasks, incurring a significant overhead. For example, in the previous WordCount MapReduce program, when a Mapper encounters multiple occurrences of the same word in a single Map task, the map function would output many <word,1> intermediate key-value pairs to be transmitted over the network. However, we can optimize this scenario if we can sum all the instances of <word,1> pairs to a single <word, count> pair before sending the data across the network to the Reducers.
To optimize such scenarios, Hadoop supports a special function called combiner, which performs local aggregation of the Map task output key-value pairs. When provided, Hadoop calls the combiner function on the Map task outputs before persisting the data on the disk to shuffle the Reduce tasks. This can significantly reduce the amount of data shuffled from the Map tasks to the Reduce tasks. It should be noted that the combiner is an optional step of the MapReduce flow. Even when you provide a combiner implementation, Hadoop may decide to invoke it only for a subset of the Map output data or may decide to not invoke it at all.
This recipe explains how to use a combiner with the WordCount MapReduce application introduced in the previous recipe.
Now let's add a combiner to the WordCount MapReduce application:
The combiner must have the same interface as the
reducefunction. Output key-value pair types emitted by the combiner should match the type of the Reducer input key-value pairs. For the WordCount sample, we can reuse the WordCountreducefunction as the combiner since the input and output data types of the WordCountreducefunction are the same.Uncomment the following line in the
WordCount.javafile to enable the combiner for the WordCount application:job.setCombinerClass(IntSumReducer.class);
Recompile the code by re-running the Gradle (
gradle build) or the Ant build (ant compile).Run the WordCount sample using the following command. Make sure to delete the old output directory (
wc-output) before running the job.$ $HADOOP_HOME/bin/hadoop jar \ hcb-c1-samples.jar \ chapter1.WordCount wc-input wc-output
The final results will be available from the
wc-outputdirectory.
When provided, Hadoop calls the combiner function on the Map task outputs before persisting the data on the disk for shuffling to the Reduce tasks. The combiner can pre-process the data generated by the Mapper before sending it to the Reducer, thus reducing the amount of data that needs to be transferred.
In the WordCount application, combiner receives N number of (word,1) pairs as input and outputs a single (word, N) pair. For example, if an input processed by a Map task had 1,000 occurrences of the word "the", the Mapper will generate 1,000 (the,1) pairs, while the combiner will generate one (the,1000) pair, thus reducing the amount of data that needs to be transferred to the Reduce tasks. The following diagram show the usage of the combiner in the WordCount MapReduce application:

Using the job's reduce function as the combiner only works when the reduce function input and output key-value data types are the same. In situations where you cannot reuse the reduce function as the combiner, you can write a dedicated reduce function implementation to act as the combiner. Combiner input and output key-value pair types should be the same as the Mapper output key-value pair types.
We reiterate that the combiner is an optional step of the MapReduce flow. Even when you provide a combiner implementation, Hadoop may decide to invoke it only for a subset of the Map output data or may decide to not invoke it at all. Care should be taken not to use the combiner to perform any essential tasks of the computation as Hadoop does not guarantee the execution of the combiner.
Using a combiner does not yield significant gains in the non-distributed modes. However, in the distributed setups as described in Setting up Hadoop YARN in a distributed cluster environment using Hadoop v2 recipe, a combiner can provide significant performance gains.
HDFS is a block structured distributed filesystem that is designed to store petabytes of data reliably on top of clusters made out of commodity hardware. HDFS supports storing massive amounts of data and provides high throughput access to the data. HDFS stores file data across multiple nodes with redundancy to ensure fault-tolerance and high aggregate bandwidth.
HDFS is the default distributed filesystem used by the Hadoop MapReduce computations. Hadoop supports data locality aware processing of data stored in HDFS. HDFS architecture consists mainly of a centralized NameNode that handles the filesystem metadata and DataNodes that store the real data blocks. HDFS data blocks are typically coarser grained and perform better with large streaming reads.
To set up HDFS, we first need to configure a NameNode and DataNodes, and then specify the DataNodes in the slaves file. When we start the NameNode, the startup script will start the DataNodes.
Tip
Installing HDFS directly using Hadoop release artifacts as mentioned in this recipe is recommended for development testing and for advanced use cases only. For regular production clusters, we recommend using a packaged Hadoop distribution as mentioned in the Setting up Hadoop ecosystem in a distributed cluster environment using a Hadoop distribution recipe. Packaged Hadoop distributions make it much easier to install, configure, maintain, and update the components of the Hadoop ecosystem.
You can follow this recipe either using a single machine or multiple machines. If you are using multiple machines, you should choose one machine as the master node where you will run the HDFS NameNode. If you are using a single machine, use it as both the name node as well as the DataNode.
Install JDK 1.6 or above (Oracle JDK 1.7 is preferred) in all machines that will be used to set up the HDFS cluster. Set the
JAVA_HOMEenvironment variable to point to the Java installation.Download Hadoop by following the Setting up Hadoop v2 on your local machine recipe.
Now let's set up HDFS in the distributed mode:
Set up password-less SSH from the master node, which will be running the NameNode, to the DataNodes. Check that you can log in to localhost and to all other nodes using SSH without a passphrase by running one of the following commands:
$ ssh localhost $ ssh <IPaddress>
Tip
Configuring password-less SSH
If the command in step 1 returns an error or asks for a password, create SSH keys by executing the following command (you may have to manually enable SSH beforehand depending on your OS):
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsaMove the
~/.ssh/id_dsa.pubfile to all the nodes in the cluster. Then add the SSH keys to the~/.ssh/authorized_keysfile in each node by running the following command (if theauthorized_keysfile does not exist, run the following command. Otherwise, skip to thecatcommand):$ touch ~/.ssh/authorized_keys && chmod 600 ~/.ssh/authorized_keysNow with permissions set, add your key to the
~/.ssh/authorized_keysfile:$ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keysThen you should be able to execute the following command successfully, without providing a password:
$ ssh localhostIn each server, create a directory for storing HDFS data. Let's call that directory
{HADOOP_DATA_DIR}. Create two subdirectories inside the data directory as{HADOOP_DATA_DIR}/dataand{HADOOP_DATA_DIR}/name. Change the directory permissions to755by running the following command for each directory:$ chmod –R 755 <HADOOP_DATA_DIR>In the NameNode, add the IP addresses of all the slave nodes, each on a separate line, to the
{HADOOP_HOME}/etc/hadoop/slavesfile. When we start the NameNode, it will use thisslavesfile to start the DataNodes.Add the following configurations to
{HADOOP_HOME}/etc/hadoop/core-site.xml. Before adding the configurations, replace the{NAMENODE}strings with the IP of the master node:<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://{NAMENODE}:9000/</value> </property> </configuration>Add the following configurations to the
{HADOOP_HOME}/etc/hadoop/hdfs-site.xmlfiles in the{HADOOP_HOME}/etc/hadoopdirectory. Before adding the configurations, replace the{HADOOP_DATA_DIR}with the directory you created in the first step. Replicate thecore-site.xmlandhdfs-site.xmlfiles we modified in steps 4 and 5 to all the nodes.<configuration> <property> <name>dfs.namenode.name.dir</name> <!-- Path to store namespace and transaction logs --> <value>{HADOOP_DATA_DIR}/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <!-- Path to store data blocks in datanode --> <value>{HADOOP_DATA_DIR}/data</value> </property> </configuration>From the NameNode, run the following command to format a new filesystem:
$ $HADOOP_HOME/bin/hdfs namenode –formatYou will see the following line in the output after the successful completion of the previous command:
… 13/04/09 08:44:51 INFO common.Storage: Storage directory /…/dfs/name has been successfully formatted. ….
Start the HDFS using the following command:
$ $HADOOP_HOME/sbin/start-dfs.shThis command will first start a NameNode in the master node. Then it will start the DataNode services in the machines mentioned in the
slavesfile. Finally, it'll start the secondary NameNode.HDFS comes with a monitoring web console to verify the installation and to monitor the HDFS cluster. It also lets users explore the contents of the HDFS filesystem. The HDFS monitoring console can be accessed from
http://{NAMENODE}:50070/. Visit the monitoring console and verify whether you can see the HDFS startup page. Here, replace{NAMENODE}with the IP address of the node running the HDFS NameNode.Alternatively, you can use the following command to get a report about the HDFS status:
$ $HADOOP_HOME/bin/hadoop dfsadmin -reportFinally, shut down the HDFS cluster using the following command:
$ $HADOOP_HOME/sbin/stop-dfs.sh
In the HDFS command-line file operations recipe, we will explore how to use HDFS to store and manage files.
The HDFS setup is only a part of the Hadoop installation. The Setting up Hadoop YARN in a distributed cluster environment using Hadoop v2 recipe describes how to set up the rest of Hadoop.
The Setting up Hadoop ecosystem in a distributed cluster environment using a Hadoop distribution recipe explores how to use a packaged Hadoop distribution to install the Hadoop ecosystem in your cluster.
Hadoop v2 YARN deployment includes deploying the ResourceManager service on the master node and deploying NodeManager services in the slave nodes. YARN ResourceManager is the service that arbitrates all the resources of the cluster, and NodeManager is the service that manages the resources in a single node.
Hadoop MapReduce applications can run on YARN using a YARN ApplicationMaster to coordinate each job and a set of resource containers to run the Map and Reduce tasks.
Tip
Installing Hadoop directly using Hadoop release artifacts, as mentioned in this recipe, is recommended for development testing and for advanced use cases only. For regular production clusters, we recommend using a packaged Hadoop distribution as mentioned in the Setting up Hadoop ecosystem in a distributed cluster environment using a Hadoop distribution recipe. Packaged Hadoop distributions make it much easier to install, configure, maintain, and update the components of the Hadoop ecosystem.
You can follow this recipe either using a single machine as a pseudo-distributed installation or using a multiple machine cluster. If you are using multiple machines, you should choose one machine as the master node where you will run the HDFS NameNode and the YARN ResourceManager. If you are using a single machine, use it as both the master node as well as the slave node.
Set up HDFS by following the Setting up HDFS recipe.
Let's set up Hadoop YARN by setting up the YARN ResourceManager and the NodeManagers.
In each machine, create a directory named local inside
{HADOOP_DATA_DIR}, whichyou created in the Setting up HDFS recipe. Change the directory permissions to755.Add the following to the
{HADOOP_HOME}/etc/hadoop/mapred-site.xmltemplate and save it as{HADOOP_HOME}/etc/hadoop/mapred-site.xml:<property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property>
Add the following to the
{HADOOP_HOME}/etc/hadoop/yarn-site.xmlfile:<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property>
Start HDFS using the following command:
$ $HADOOP_HOME/sbin/start-dfs.shRun the following command to start the YARN services:
$ $HADOOP_HOME/sbin/start-yarn.sh starting yarn daemons starting resourcemanager, logging to ……… xxx.xx.xxx.xxx: starting nodemanager, logging to ………
Run the following command to start the MapReduce JobHistoryServer. This enables the web console for MapReduce job histories:
$ $HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserverVerify the installation by listing the processes through the
jpscommand. The master node will list the NameNode, ResourceManager, and JobHistoryServer services. The slave nodes will list DataNode and NodeManager services:$ jps 27084 NameNode 2073 JobHistoryServer 2106 Jps 2588 1536 ResourceManager
Visit the web-based monitoring pages for ResourceManager available at
http://{MASTER_NODE}:8088/.
As described in the introduction to the chapter, Hadoop v2 installation consists of HDFS nodes, YARN ResourceManager, and worker nodes. When we start the NameNode, it finds slaves through the HADOOP_HOME/slaves file and uses SSH to start the DataNodes in the remote server at the startup. Also, when we start ResourceManager, it finds slaves through the HADOOP_HOME/slaves file and starts NodeManagers.
The Hadoop YARN ecosystem now contains many useful components providing a wide range of data processing, storing, and querying functionalities for the data stored in HDFS. However, manually installing and configuring all of these components to work together correctly using individual release artifacts is quite a challenging task. Other challenges of such an approach include the monitoring and maintenance of the cluster and the multiple Hadoop components.
Luckily, there exist several commercial software vendors that provide well integrated packaged Hadoop distributions to make it much easier to provision and maintain a Hadoop YARN ecosystem in our clusters. These distributions often come with easy GUI-based installers that guide you through the whole installation process and allow you to select and install the components that you require in your Hadoop cluster. They also provide tools to easily monitor the cluster and to perform maintenance operations. For regular production clusters, we recommend using a packaged Hadoop distribution from one of the well-known vendors to make your Hadoop journey much easier. Some of these commercial Hadoop distributions (or editions of the distribution) have licenses that allow us to use them free of charge with optional paid support agreements.
Hortonworks Data Platform (HDP) is one such well-known Hadoop YARN distribution that is available free of charge. All the components of HDP are available as free and open source software. You can download HDP from http://hortonworks.com/hdp/downloads/. Refer to the installation guides available in the download page for instructions on the installation.
Cloudera CDH is another well-known Hadoop YARN distribution. The Express edition of CDH is available free of charge. Some components of the Cloudera distribution are proprietary and available only for paying clients. You can download Cloudera Express from http://www.cloudera.com/content/cloudera/en/products-and-services/cloudera-express.html. Refer to the installation guides available on the download page for instructions on the installation.
Hortonworks HDP, Cloudera CDH, and some of the other vendors provide fully configured quick start virtual machine images that you can download and run on your local machine using a virtualization software product. These virtual machines are an excellent resource to learn and try the different Hadoop components as well as for evaluation purposes before deciding on a Hadoop distribution for your cluster.
Apache Bigtop is an open source project that aims to provide packaging and integration/interoperability testing for the various Hadoop ecosystem components. Bigtop also provides a vendor neutral packaged Hadoop distribution. While it is not as sophisticated as the commercial distributions, Bigtop is easier to install and maintain than using release binaries of each of the Hadoop components. In this recipe, we provide steps to use Apache Bigtop to install Hadoop ecosystem in your local machine.
Any of the earlier mentioned distributions, including Bigtop, is suitable for the purposes of following the recipes and executing the samples provided in this book. However, when possible, we recommend using Hortonworks HDP, Cloudera CDH, or other commercial Hadoop distributions.
This recipe provides instructions for the Cent OS and Red Hat operating systems. Stop any Hadoop service that you started in the previous recipes.
The following steps will guide you through the installation process of a Hadoop cluster using Apache Bigtop for Cent OS and Red Hat operating systems. Please adapt the commands accordingly for other Linux-based operating systems.
Install the Bigtop repository:
$ sudo wget -O \ /etc/yum.repos.d/bigtop.repo \ http://www.apache.org/dist/bigtop/stable/repos/centos6/bigtop.repo
Search for Hadoop:
$ yum search hadoopInstall Hadoop v2 using Yum. This will install Hadoop v2 components (MapReduce, HDFS, and YARN) together with the ZooKeeper dependency.
$ sudo yum install hadoop\*Use your favorite editor to add the following line to the
/etc/default/bigtop-utilsfile. It is recommended to pointJAVA_HOMEto a JDK 1.6 or later installation (Oracle JDK 1.7 or higher is preferred).export JAVA_HOME=/usr/java/default/
Initialize and format the NameNode:
$ sudo /etc/init.d/hadoop-hdfs-namenode initStart the Hadoop NameNode service:
$ sudo service hadoop-hdfs-namenode startStart the Hadoop DataNode service:
$ sudo service hadoop-hdfs-datanode startRun the following script to create the necessary directories in HDFS:
$ sudo /usr/lib/hadoop/libexec/init-hdfs.shCreate your home directory in HDFS and apply the necessary permisions:
$ sudo su -s /bin/bash hdfs \ -c "/usr/bin/hdfs dfs -mkdir /user/${USER}" $ sudo su -s /bin/bash hdfs \ -c "/usr/bin/hdfs dfs -chmod -R 755 /user/${USER}" $ sudo su -s /bin/bash hdfs \ -c "/usr/bin/hdfs dfs -chown ${USER} /user/${USER}"
Start the YARN ResourceManager and the NodeManager:
$ sudo service hadoop-yarn-resourcemanager start $ sudo service hadoop-yarn-nodemanager start $ sudo service hadoop-mapreduce-historyserver start
Try the following commands to verify the installation:
$ hadoop fs -ls / $ hadoop jar \ /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar \ pi 10 1000
You can also monitor the status of the HDFS using the monitoring console available at
http://<namenode_ip>:50070.Install Hive, HBase, Mahout, and Pig using Bigtop as follows:
$ sudo yum install hive\*, hbase\*, mahout\*, pig\*
You can use the Puppet-based cluster installation of Bigtop by following the steps given at https://cwiki.apache.org/confluence/display/BIGTOP/How+to+install+BigTop+0.7.0+hadoop+on+CentOS+with+puppet
You can also set up your Hadoop v2 clusters in a cloud environment as we will discuss in the next chapter
HDFS is a distributed filesystem, and just like any other filesystem, it allows users to manipulate the filesystem using shell commands. This recipe introduces some of these commands and shows how to use the HDFS shell commands.
It is worth noting that some of the HDFS commands have a one-to-one correspondence with the mostly used Unix commands. For example, consider the following command:
$ bin/hdfs dfs –cat /user/joe/foo.txt
The command reads the /user/joe/foo.txt file and prints it to the screen, just like the cat command in a Unix system.
Start the HDFS server by following the Setting up HDFS recipe or the Setting up Hadoop ecosystem in a distributed cluster environment using a Hadoop distribution recipe.
Run the following command to list the content of your HDFS home directory. If your HDFS home directory does not exist, please follow step 9 of the Setting up Hadoop ecosystem in a distributed cluster environment using a Hadoop distribution recipe to create your HDFS home directory.
$ hdfs dfs -lsRun the following command to create a new directory called
testinside your home directory in HDFS:$ hdfs dfs -mkdir testThe HDFS filesystem has
/as the root directory. Run the following command to list the content of the newly created directory in HDFS:$ hdfs dfs -ls testRun the following command to copy the local readme file to
test:$ hdfs dfs -copyFromLocal README.txt testRun the following command to list the
testdirectory:$ hdfs dfs -ls test Found 1 items -rw-r--r-- 1 joesupergroup1366 2013-12-05 07:06 /user/joe/test/README.txt
Run the following command to copy the
/test/README.txtfile back to a local directory:$ hdfs dfs –copyToLocal \ test/README.txt README-NEW.txt
When the command is issued, the HDFS client will talk to HDFS NameNode on our behalf and carry out the operation. The client will pick up the NameNode from the configurations in the HADOOP_HOME/etc/hadoop/conf directory.
However, if needed, we can use a fully qualified path to force the client to talk to a specific NameNode. For example, hdfs://bar.foo.com:9000/data will ask the client to talk to NameNode running on bar.foo.com at the port 9000.
HDFS supports most of the Unix commands such as cp, mv, and chown, and they follow the same pattern as the commands discussed earlier. The following command lists all the available HDFS shell commands:
$ hdfs dfs -help
Using a specific command with help will display the usage of that command.
$ hdfs dfs –help du
This recipe describes how to run a MapReduce computation in a distributed Hadoop v2 cluster.
Start the Hadoop cluster by following the Setting up HDFS recipe or the Setting up Hadoop ecosystem in a distributed cluster environment using a Hadoop distribution recipe.
Now let's run the WordCount sample in the distributed Hadoop v2 setup:
Upload the
wc-inputdirectory in the source repository to the HDFS filesystem. Alternatively, you can upload any other set of text documents as well.$ hdfs dfs -copyFromLocal wc-input .Execute the WordCount example from the
HADOOP_HOMEdirectory:$ hadoop jar hcb-c1-samples.jar \ chapter1.WordCount \ wc-input wc-output
Run the following commands to list the output directory and then look at the results:
$hdfs dfs -ls wc-output Found 3 items -rw-r--r-- 1 joesupergroup0 2013-11-09 09:04 /data/output1/_SUCCESS drwxr-xr-x - joesupergroup0 2013-11-09 09:04 /data/output1/_logs -rw-r--r-- 1 joesupergroup1306 2013-11-09 09:04 /data/output1/part-r-00000 $ hdfs dfs -cat wc-output/part*
When we submit a job, YARN would schedule a MapReduce ApplicationMaster to coordinate and execute the computation. ApplicationMaster requests the necessary resources from the ResourceManager and executes the MapReduce computation using the containers it received from the resource request.
Hadoop contains several benchmarks that you can use to verify whether your HDFS cluster is set up properly and performs as expected. DFSIO is a benchmark test that comes with Hadoop, which can be used to analyze the I/O performance of an HDFS cluster. This recipe shows how to use DFSIO to benchmark the read/write performance of an HDFS cluster.
You must set up and deploy HDFS and Hadoop v2 YARN MapReduce prior to running these benchmarks. Locate the hadoop-mapreduce-client-jobclient-*-tests.jar file in your Hadoop installation.
The following steps will show you how to run the write and read DFSIO performance benchmarks:
Execute the following command to run the HDFS write performance benchmark. The
–nrFilesparameter specifies the number of files to be written by the benchmark. Use a number high enough to saturate the task slots in your cluster. The-fileSizeparameter specifies the file size of each file in MB. Change the location of thehadoop-mapreduce-client-jobclient-*-tests.jarfile in the following commands according to your Hadoop installation.$ hadoop jar \ $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-*-tests.jar \ TestDFSIO -write -nrFiles 32 –fileSize 1000
The write benchmark writes the results to the console as well as appending to a file named
TestDFSIO_results.log. You can provide your own result filename using the–resFileparameter.The following step will show you how to run the HDFS read performance benchmark. The read performance benchmark uses the files written by the write benchmark in step 1. Hence, the write benchmark should be executed before running the read benchmark and the files written by the write benchmark should exist in the HDFS for the read benchmark to work properly. The benchmark writes the results to the console and appends the results to a logfile similarly to the write benchmark.
$hadoop jar \ $HADOOP_HOME/share/Hadoop/mapreduce/hadoop-mapreduce-client-jobclient-*-tests.jar \ TestDFSIO -read \ -nrFiles 32 –fileSize 1000
The files generated by the preceding benchmarks can be cleaned up using the following command:
$hadoop jar \ $HADOOP_HOME/share/Hadoop/mapreduce/hadoop-mapreduce-client-jobclient-*-tests.jar \ TestDFSIO -clean
DFSIO executes a MapReduce job where the Map tasks write and read the files in parallel, while the Reduce tasks are used to collect and summarize the performance numbers. You can compare the throughput and IO rate results of this benchmark with the total number of disks and their raw speeds to verify whether you are getting the expected performance from your cluster. Please note the replication factor when verifying the write performance results. High standard deviation in these tests may hint at one or more underperforming nodes due to some reason.
Hadoop TeraSort is a well-known benchmark that aims to sort 1 TB of data as fast as possible using Hadoop MapReduce. TeraSort benchmark stresses almost every part of the Hadoop MapReduce framework as well as the HDFS filesystem making it an ideal choice to fine-tune the configuration of a Hadoop cluster.
The original TeraSort benchmark sorts 10 million 100 byte records making the total data size 1 TB. However, we can specify the number of records, making it possible to configure the total size of data.
You must set up and deploy HDFS and Hadoop v2 YARN MapReduce prior to running these benchmarks, and locate the hadoop-mapreduce-examples-*.jar file in your Hadoop installation.
The following steps will show you how to run the TeraSort benchmark on the Hadoop cluster:
The first step of the TeraSort benchmark is the data generation. You can use the
teragencommand to generate the input data for the TeraSort benchmark. The first parameter ofteragenis the number of records and the second parameter is the HDFS directory to generate the data. The following command generates 1 GB of data consisting of 10 million records to thetera-indirectory in HDFS. Change the location of thehadoop-mapreduce-examples-*.jarfile in the following commands according to your Hadoop installation:$ hadoop jar \ $HADOOP_HOME/share/Hadoop/mapreduce/hadoop-mapreduce-examples-*.jar \ teragen 10000000 tera-in
Tip
It's a good idea to specify the number of Map tasks to the
teragencomputation to speed up the data generation. This can be done by specifying the–Dmapred.map.tasksparameter.Also, you can increase the HDFS block size for the generated data so that the Map tasks of the TeraSort computation would be coarser grained (the number of Map tasks for a Hadoop computation typically equals the number of input data blocks). This can be done by specifying the
–Ddfs.block.sizeparameter.$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar \ teragen –Ddfs.block.size=536870912 \ –Dmapred.map.tasks=256 10000000 tera-in
The second step of the TeraSort benchmark is the execution of the TeraSort MapReduce computation on the data generated in step 1 using the following command. The first parameter of the
terasortcommand is the input of HDFS data directory, and the second part of theterasortcommand is the output of the HDFS data directory.$ hadoop jar \ $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar \ terasort tera-in tera-out
Tip
It's a good idea to specify the number of Reduce tasks to the TeraSort computation to speed up the Reducer part of the computation. This can be done by specifying the
–Dmapred.reduce.tasksparameter as follows:$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar terasort –Dmapred.reduce.tasks=32 tera-in tera-outThe last step of the TeraSort benchmark is the validation of the results. This can be done using the
teravalidateapplication as follows. The first parameter is the directory with the sorted data and the second parameter is the directory to store the report containing the results.$ hadoop jar \ $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar \ teravalidate tera-out tera-validate
