


















 Download code from GitHub
Download code from GitHub
In this chapter, we'll cover the following recipes:
- Generative and discriminative models
- A neural network love story
- Deep neural networks
- Architecture structure basics
- Basic building block- generator
- Basic building block – loss functions
- Training
- GAN pieces come together in different ways
- What does a GAN output?
- Understanding the benefits of a GAN structure
I'm sure you've heard of a neural network dreaming? Maybe you've heard that AI is coming for you? Well, I'm here to tell you that there's no need to worry just yet. A Neural Network dreaming isn't too far away from the truth though. Generative Adversarial Networks (GANs), represent a shift in architecture design for deep neural networks. This new architecture pits two or more neural networks against each other in adversarial training to produce generative models. Throughout this book, we'll focus on covering the basic implementation of this architecture and then focus on modern representations of this new architecture in the form of recipes.
GANs are a hot topic of research today in the field of deep learning. Popularity has soared with this architecture style, with it's ability to produce generative models that are typically hard to learn. There are a number of advantages to using this architecture: it generalizes with limited data, conceives new scenes from small datasets, and makes simulated data look more realistic. These are important topics in deep learning because many techniques today require large amounts of data. Using this new architecture, it's possible to drastically reduce the amount of data needed to complete these tasks. In extreme examples, these types of architectures can use 10% of the data needed for other types of deep learning problems.
By the end of this chapter, you'll have learned about the following concepts:
- Do all GANs have the same architecture?
- Are there any new concepts within the GAN architecture?
- The basic construction of the GAN architecture in practice
Ready, set, go!
Machine learning (ML) and deep learning can be described by two terms: generative and discriminative modeling. When discussing the machine learning techniques that most people are familiar with, the thinking of a discriminative modeling technique, such as classification.
The difference between these two types of can be described by the following analogy:
Here are a few steps that describe how we would do this in machine learning:
- First, we create a machine learning model that use convolutional layers or other learned features to understand the divisions in the data
- Next, we collect a dataset that has both a training set (60-90% of your data) and a validation dataset (10-40% of your data)
- Train the machine learning model using your data
- Use this model to predict which datapoint belongs to a particular class - in our example, which painting belongs to which author
Here are a few steps to describe a possible way to accomplish this type of modeling:
- Create a machine learning model that learns how to reproduce different painting styles
- Collect a training and validation dataset
- Train the machine learning model using the data
- Use this model to predict (inference) to produce examples of the paint author - use similarity metrics to verify the ability of the model to reproduce the painting style.
Discriminative models will learn the boundary conditions between classes for a distribution:
- Discriminative models get their power from more data
- These models are not designed to work in an unsupervised manner or with unlabeled data
This can be described in a more graphical way, as follows:

This can be described in a more graphical way, as follows:

So, generative models are incredibly difficult to produce as they have to accurately model and reproduce the input distribution. The discriminative models are learning decision boundaries, which is why neural networks have been incredibly successful in recent years. The GAN architecture represents a radical departure from older techniques in the generative modeling area. We'll cover how neural networks are developed and then dive right in the GAN architecture development.
Since you've come here to learn more about a specific neural network architecture, we're going to assume you have a baseline understanding of current machine and deep learning techniques that revolve around neural networks. Neural networks have exploded in popularity since the advent of the deep neural network-style architectures. By utilizing many hidden layers and large sums of data, modern deep learning techniques are able to exceed human-level performance in a dizzying number of applications. How is this possible? Neural networks are now able to learn baseline features and relationships in similar ways to our brains. Along those same lines, researchers have been exploring new styles of mixing neural networks to replicate the thought process that our brains take automatically.
The story is a classic: researcher goes drinking with a few friends and has an epiphany- what if you were able to pit two neural networks against each other to solve a problem? Ian Goodfellow, affectionately called the GANfather, helped popularize this adversarial architecture with his hallmark paper in 2014, called Generative Adversarial Networks. Researchers all over the world began developing variations on this technique: can you pit three or more networks against each other? What happens when you provide more than one loss function? These are actually the types of questions you should be able to answer by the end of this book, because we'll focus on implementing modern renditions of this architecture to solve these types of problems.
It's important to understand the difference and difficulties that surround generative and discriminative modeling. In recent years, discriminative modeling has seen some great successes. Typically requiring Markov decision processes in order for the generative modeling process to work, these techniques suffered from a lack of flexibility without heavy design tuning. That is, until the advent of the GANs architecture that we're discussing today. Goodfellow adequately summed up the issues surrounding discriminative and generative models in his paper in 2014:

Goodfellow and his coauthors presented a graphic on the challenges associated with generative modeling in the literature up until 2014
What are Goodfellow and his fellow authors getting at in this screenshot? Essentially, prior generative models were painful to train/build. GANs can have their challenges in terms of training and design, but represent a fundamental shift in flexibility in output given the ease of setup. In the Chapter 3, My First GAN in Under 100 Lines, we'll build a GAN network in under 100 lines of code.
But first, let's review the concept of a deep neural network. A neural network, in ML, represents a technique to mimic the same neurological processes that occur in our brain. Neurons, like those in our brains, represent the basic building blocks of the neural network architecture that we use to learn and retain a baseline set of information around our knowledge.
Our neurological process uses previous experience as examples, learning a structure to understand the data and form a conclusion or output:

Neurons making connections to go from input to hidden layer to single output
This basic architecture will form the foundation of our deep neural network, which we'll present in the next section.
Here are the basic steps of how the model is built:
- An input (an image or other input data) is sent into an input (static) layer
- The single or series of hidden layer then operates on this data
- The output layer aggregates all of this information into an output format
Originally conceived in the early 1940s as a mathematical construct, the artificial neural network was popularized in the 1980s through a method called backpropagation. Backprop, for short, allows an artificial neural network to adjust the weights of each layer at every epoch of training. In the 1980s, the limits of computational power only allowed for a certain level of training. As the computing power expanded and the research grew, there was a renaissance with ML.
With the advent of cheap computing power, a new technique was born: deep neural networks. Utilizing the ability of GPUs to compute tensors very quickly, a few libraries have been developed to build these deep neural networks. To become a deep neural network, the basic premise is this: add four or more hidden layers between the input and output. Typically, there are thousands of neurons in the graph and the neural network has a much larger capacity to learn. This construct is illustrated in the following diagram:

A deep neural network is a relatively simple expansion of the basic architecture of the neural network
This represents the basic architecture for how a deep neural network is structured. There are plenty of modifications and basic restructuring of this architecture, but this basic graph provides the right pieces to implement a Deep Neural Network. How does all of this fit into GANs? Deep neural networks are a critical piece of the GAN architecture, as you'll see in the next section.
Note
Practice building neural network architectures in frameworks such as scikit-learn or Keras to understand fundamental concepts. It's beneficial to understand the differences in various types of dropout and activation functions. These tools will serve you well as you work through the examples in this book.
Now, this is the part you've been waiting for: how do I build a GAN? There are a few principal components to the construction of this network architecture. First, we need to have a method to produce neural networks easily, such as Keras or PyTorch (using the TensorFlow backend). This critical piece will be covered extensively in Chapter 2, Data First Easy Environment, and Data Prep and Chapter 3, My First GAN in Under 100 Lines. Second, we need to produce the two neural-network-based components, named the generator and discriminator.
The classic analogy is the counterfeiter (generator) and FBI agent (discriminator). The counterfeiter is constantly looking for new ways to produce fake documents that can pass the FBI agent's tests. Let's break it down into a set of goals:
- Counterfeiter (generator) goal: Produce products so that the cop cannot distinguish between the real and fake ones
- Cop (discriminator) goal: Detect anomalous products by using prior experience to classify real and fake products
Now, enough with the analogies, right? Let's restructure this into a game-theory-style problem-the minimax problem from the first GAN implementation. The following steps illustrate how we can create this type of problem:
- Generator goal: Maximize the likelihood that the discriminator misclassifies its output as real
- Discriminator goal: Optimize toward a goal of 0.5, where the discriminator can't distinguish between real and generated images
Note
The Minimax Problem (sometimes called MinMax) is a theory that focuses on maximizing a function at the greatest loss (or vice versa). In the case of GANs, this is represented by the two models training in an adversarial way. The training step will focus on minimizing the error on the training loss for the generator while getting as close to 0.5 as possible on the discriminator (where the discriminator can't tell the difference between real and fake).
In the GAN framework, the generator will start to train alongside the discriminator; the discriminator needs to train for a few epochs prior to starting the adversarial training as the discriminator will need to be able to actually classify images. There's one final piece to this structure, called the loss function. The loss function provides the stopping criteria for the Generator and Discriminator training processes. Given all of these pieces, how do we structure these pieces into something we can train? Check out the following diagram:

A high-level description of the flow of the Generative Adversarial Network, showing the basic functions in block format
With this architecture, it's time to break each piece into its component technology: generator, discriminator, and loss function. There will also be a section on training and inference to briefly cover how to train the model and get data out once it is trained.
It's important to focus on each of these components to understand how they come together. For each of these sections, I'll be highlighting the architecture pieces to make it more apparent.
The following diagram represents the important pieces of the generator:

The generator components in the architecture diagram: latent space, generator, and image generation by the generator
The focus in the diagram ensures that you see the core piece of code that you'll be developing in the generator section.
Here are a few steps to describe how we create a generator conceptually:
- First, the generator samples from a latent space and creates a relationship between the latent space and the output
- We then create a neural network that goes from an input (latent space) to output (image for most examples)
- We'll train the generator in an adversarial mode where we connect the generator and discriminator together in a model ( every generator and GAN recipe in this book will show these steps)
- The generator can then be used for inference after training
Each of these building blocks is fairly unique, but the generator is arguably the most important concept to understand. Ultimately, the generator will produce the images or output that we see after this entire training process is complete. When we talk about training GANs, it refers directly to training the generator. As we mentioned in a previous section, the discriminator will need to train for a few epochs prior to beginning the training process in most architectures or it would never complete training.
For each of these sections, it is important to understand the structure of the code we'll start building through the course of this book. In each chapter, we're going to define classes for each of the components. The generator will need to have three main functions within the class:

Class template for developing the generator – these represent the basic components we need to implement for each of our generator classes
The loss function will define a custom loss function in training the model (if needed for that particular implementation). The buildModel function will construct the actual model of the given neural network. Specific training sequences for a model will go inside this class though we'll likely not use the internal training methods for anything but the discriminator.
The generator generates the data in the GAN architecture, and now we are going to introduce the Discriminator architecture. The discriminator is used to determine whether the output of the generator and a real image are real or fake.
The discriminator architecture determines whether the image is real or fake. In this case, we are focused solely on the neural network that we are going to create- this doesn't involve the training step that we'll cover in the training recipe in this chapter:
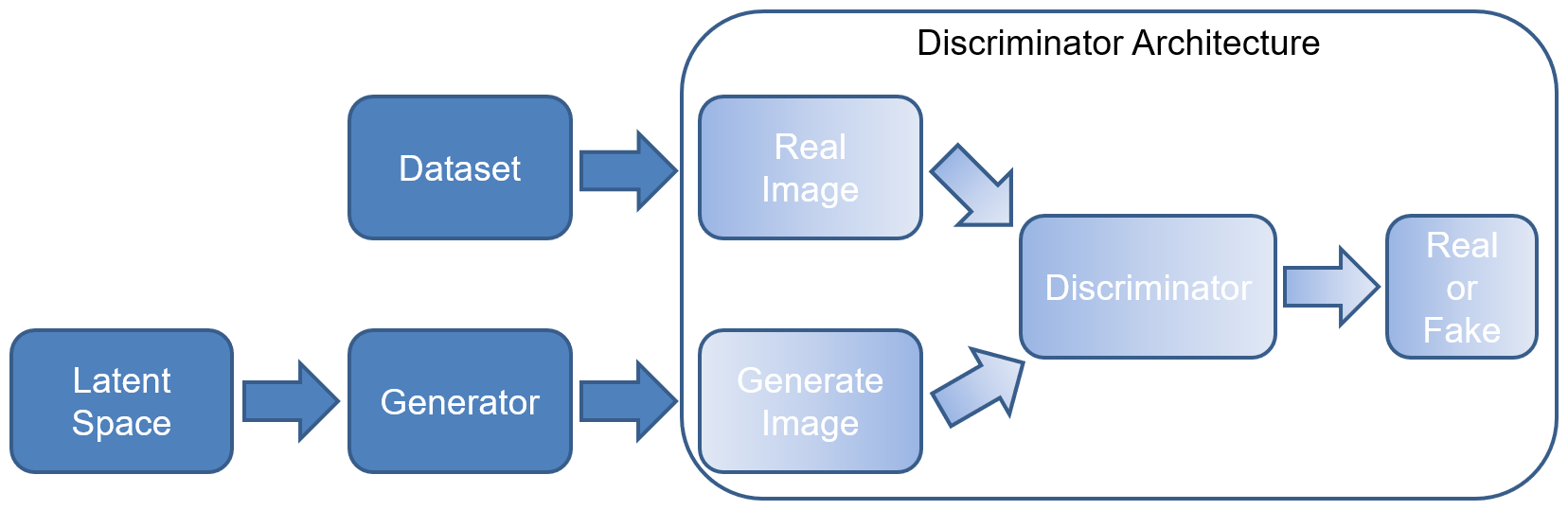
The basic components of the discriminator architecture
The discriminator is typically a simple Convolution Neural Network (CNN) in simple architectures. In our first few examples, this is the type of neural network we'll be using.
Here are a few steps to illustrate how we would build a discriminator:
- First, we'll create a convolutional neural network to classify real or fake (binary classification)
- We'll create a dataset of real data and we'll use our generator to create fake dataset
- We train the discriminator model on the real and fake data
- We'll learn to balance training of the discriminator with the generator training - if the discriminator is too good, the generator will diverge
So, why even use the discriminator in this case? The discriminator is able to take all of the good things we have with discriminative models and act as an adaptive loss function for the GAN as a whole. This means that the discriminator is able to adapt to the underlying distribution of data. This is one of the reasons that current deep learning discriminative models are so successful today—in the past, techniques relied too heavily on directly computing some heuristic on the underlying data distribution. Deep neural networks today are able to adapt and learn based on the distribution of the data, and the GAN technique takes advantage of that.
Ultimately, the discriminator is going to evaluate the output of the real image and the generated image for authenticity. The real images will score high on the scale initially, while the generated images will score lower. Eventually, the discriminator will have trouble distinguishing between the generated and real images. The discriminator will rely on building a model and potentially an initial loss function. The following class template will be used throughout this book to represent the discriminator:

Class template for developing the discriminator—these represent the basic components we need to implement for each of our discriminator classes
In the end, the discriminator will be trained along with the generator in a sequential model; we'll only use the trainModel method in this class for specific architectures. For the sake of simplicity and uniformity, the method will go unimplemented in most recipes.
Each neural network has certain structural components in order to train. The process of training is tuning the weights to optimize the loss function for the given problem set. The loss function selected for the neural network therefore is essential to ensure the neural network produces good results and converges.
The generator is a neural network and requires a loss function. So, what kind of loss function should we employ in this architecture? That's almost as fundamental a question as what car you should drive. The loss functions need to be selected appropriately for the Generator to converge with the caveat that the loss function selection will depend on what's your goal for it.
Each of the diverse architectures we'll cover in this book will use different tools to get different results. Take, for instance, the generator loss function from the initial GAN paper by Goodfellow and his associates:

Loss function used with the Generator in adversarial training
This equation simply states that the discriminator is minimizing the log probability that the discriminator is correct. It's part of the adversarial mode of training that occurs. Another thing to consider in this context is that the loss function of the generator does matter. Gradient Saturation, an issue that occurs when the learning gradients are near zero and make learning nearly impossible, can occur for poorly-designed loss functions. The selection of the correct loss function is imperative even for the generator.
Now, let's check out the loss function of the discriminator from the Goodfellow paper:

Standard cross-entropy implementation applied to GANs
This is a standard cross-entropy implementation. Essentially, one of the unique things about this equation is how it is trained through multiple mini-batches. We'll talk about that in a later section in this chapter.
As mentioned before, the discriminator acts as a learned loss function for the overall architecture. When building each of the models though and in paired GAN architectures, it is necessary to have multiple loss functions. In this case, let's define a template class for the loss function in order to store these loss methods:

The class template for loss functions that will be optionally implemented depending on the availability of the lost functions used
During the development of these recipes, we are going to come back to these templates over and over again. A bit of standardization to the code base will go a long way in ensuring that your code remains readable and maintainable.
Have you got all the pieces? We're ready to go, right? WRONG! We need to understand the best a strategy for how we can train this type of architecture.
The GAN model relies on so-called adversarial training. You'll notice in the following diagram that there are two seemingly conflicting error functions being minimized/maximized.
We've talked about the MiniMax problem at work here. By sampling two mini-batches at every epoch, the GAN architecture is able to simultaneously maximize the error to the generator and minimize the error to the discriminator:

Architecture diagram updated to show the backpropagation step in training the GAN model
In each chapter, we'll revisit what it means to train a GAN. Generative models are notoriously difficult to train to get good results. GANs are no different in this respect. There are tips and tricks that you will learn throughout this book in order to get your models to converge and produce results.
We have explored a few simple GAN structures; we are going to look at seven different styles of GANs in this book. The important thing to realize about the majority of these papers is that the changes occur on the generator and the loss functions.
The generator is going to be producing the images or output, and the loss function will drive the training process to optimize different functions. In practice, what types of variation will there be? Glad you're here. Let's take a brief look at the different architectures.
Let's discuss the simplest concept to understand with GANs: style transfer. This type of methodology manifests itself in many different variations, but one of the things I find fascinating is that the architecture of the GAN needs to change based on the specific type of transfer that needs to occur. For instance, one of the papers coming out of Adobe Research Labs focuses on makeup application and removal. Can you apply the same style of makeup as seen in a photo to a photo of another person? The architecture itself is actually rather advanced to make this happen in a realistic fashion, as seen by the architecture diagram:

This particular architecture is one of the most advanced to date-there are five separate loss functions! One of the interesting things about this architecture is that it is able to simultaneously learn a makeup application and makeup removal function. Once the GAN understands how to apply the makeup, it already has a source image to remove the makeup. Along with the five loss functions, the generator is fairly unique in its construction, as given by the following diagram:

So, why does this even matter? One of the recipes we are going to cover is style transfer, and you'll see during that particular recipe that our GAN model won't be this advanced. Why is that? In constructing a realistic application of makeup, it takes additional loss functions to appropriately tune the model into fooling the discriminator. In the case of transferring a painter's style, it is easier to transfer a uniform style than multiple disparate makeup styles, like you would see in the preceding data distribution.
So, we've seen the different structures and types of GANs. We know that GANs can be used for a variety of tasks. But, what does a GAN actually output? Similar to the structure of a neural network (deep or otherwise), we can expect that the GAN will be able to output any value that a neural network can produce. This can take the form of a value, an image, or many other types of variables. Nowadays, we usually use the GAN architecture to apply and modify images.
Let's take a few examples to explore the power of GANs. One of the great parts about this section is that you will be able to implement every one of these architectures by the end of this book. Here are the topics we'll cover in the next section:
- Working with limited data – style transfer
- Dreaming new scenes – DCGAN
- Enhancing simulated data – SimGAN
There are three core sections we want to discuss here that involve typical applications of GANs: style transfer, DCGAN, and enhancing simulated data.
Have you ever seen a neural network that was able to easily convert a photo into a famous painter's style, such as Monet? GAN architecture is often employed for this type of network, called style transfer, and we'll learn how to do style transfer in one of our recipes in this book. This represents one of the simplest applications of generative adversarial network architecture that we can apply quickly. A simple example of the power of this particular architecture is shown here:

Image A represents in the input and Image B represents the style transferred image. The <style> has been applied to this input image.
One of the unique things about these agents is that they require fewer examples than the typical deep learning techniques you may be familiar with. With famous painters, there aren't that many training examples for each of their styles, which produces a very limited dataset and it took more advanced techniques in the past to replicate their painting styles. Today, this technique will allow all of us to find our inner Monet.
We talked about the network dreaming a new scene. Here's another powerful example of the GAN architecture. The Deep Convolution Generative Adversarial Network (DCGAN) architecture allows a neural network to operate in the opposite direction of a typical classifier. An input phrase goes into the network and produces an image output. The network that produces output images is attempting to beat a discriminator based on a classic CNN architecture.
Once the generator gets past a certain point, the discriminator stops training (https://www.slideshare.net/enakai/dcgan-how-does-it-work) and the following image shows how we go from an input to an output image with the DCGAN architecture:

Image A represents in the input and Image B represents the style transferred image; the input image now represents the conversion of the input to the new output space
Ultimately, the DCGAN takes in a set of random numbers (or numbers derived from a word, for instance) and produces an image. DCGANs are fun to play with because they learn relationships between an input and their corresponding label. If we attempted to use a word the model has never seen, it'll still produce an output image. I wonder what types of image the model will give us for words it has never seen.
Apple recently released the simGAN paper focused on making simulated images look real-how? They used a particular GAN architecture, called simGAN, to improve images of eyeballs. Why is this problem interesting? Imagine realistic hands with no models needed. It provides a whole new avenue and revenue stream for many companies once these techniques can be replicated in real life. Using the simGAN architecture, you'll notice that the actual network architectures aren't that complicated:

A simple example of the simGAN architecture. The architecture and implementation will be discussed at length
The real secret sauce is in the loss function that the Apple developers used to train the networks. A loss function is how the GAN is able to know when to stop training the GAN. Here’s the powerful piece to this architecture: labeled real data can be expensive to produce or generate. In terms of time and cost, simulated data with perfect labels is easy to produce and the trade space is controllable.
So, what kinds of cool tidbits did you learn in this particular chapter? I'll try to use this final chapter as a recap of why the GAN structure is cool and what kinds of things make this a powerful tool for your future research.
As a recap, we start with three key questions:
- Are GANs all the same architecture?
- Are there any new concepts within the GAN architecture?
- How do we practically construct the GAN Architecture?
We'll also review the key takeaways from this chapter.
Let's address these three key questions:
- Are GANs all the same architecture?
- GANs come in all shapes and sizes. There are simple implementations and complex ones. It just depends what domain you are approaching and what kind of accuracy you need in the generated input.
- Are there any new concepts within the GAN architecture?
- GANs rely heavily on advances in the deep learning world around Deep Neural Networks. The novel part of a GAN lies in the architecture and the adversarial nature of training two (or more) neural networks against each other.
- How do we practically construct the GAN architecture architecture?:
- The generator, discriminator, and associated loss functions are fundamental building blocks that we'll pull on for each of the chapters in order to build these models.
What are the key things to remember from this chapter?
- The initial GAN paper was only the beginning of a movement within the machine learning space
- The generator and discriminator are neural networks in a unique training configuration
- The loss functions are critical to ensuring that the architecture can converge during training
You really didn't think I'd let you get out of this chapter without some homework, did you? I've got a few basic problems to get you ready for the following lessons:
- Produce a CNN based on ImageNet to classify all of the MSCOCO classes.
Hint: There are plenty of available models out there. Simply get one running in inference mode and see how it works.
- Draw the basic GAN architecture. Now, draw an improvement to that architecture based on the topics you learned in this chapter. Think of the generator and discriminator as building blocks.





