


















Getting Started with Data Exploration
Apache Superset is a web platform for creating data visualizations and telling stories with data using dashboards. Packing visualizations in a dashboard is fun, and dashboards render updates to the visualizations in real time.
The best part is that Superset has a very interactive user experience. Programming knowledge is not required for using Superset.
Superset makes it easy to share and collaborate on data analytics work. It has user roles and permission management built into it as core components. This makes it a great choice for data analysis work collaboration between a cross functional team of data analysts, business professionals, and software engineers.
There all sorts of charts to make on Superset. Many common analytical questions on data can be addressed using the charts, which are easy to use. In this book, we will do data exploration and analysis of different types of datasets. In the process, we will try to understand different aspects of Superset.
In this chapter, we will learn about the following:
- Datasets
- Installing Superset
- Sharing Superset
- Configuring Superset
- Adding a database
- Adding a table
- Creating a chart
- Uploading a CSV file
- Configuring a table schema
- Customizing the visualization
- Making a dashboard
Datasets
We will be working on a variety of datasets in this book, and we will analyze their data. We will make many charts along the way. Here is how we will go about it:
- Visualizing data distributions:
- Headlines
- Distributions
- Comparisons
- Finding trends in time series or multi-feature datasets:
- Joint distributions with time series data
- Joint distributions with a size feature
- Joint distributions
- Discovering hierarchical and graphical relationships between features:
- Hierarchical maps
- Path maps
- Plotting features with location information on maps:
- Heatmaps using Mapbox
- 2D maps using Mapbox
- 3D maps using MapGL
- World map
Superset plugs into any SQL database that has a Python SQLAlchemy connector, such as PostgreSQL, MySQL, SQLite, MongoDB, and Snowflake. The data stored in any of the databases is fetched for making charts. Most database documents have a requirement for the Python SQLAlchemy connector.
In this book, we will use Google BigQuery and PostgreSQL as our database. Our datasets will be public tables from Google BigQuery and .csv files from a variety of web resources, which we will upload to PostgreSQL. The datasets cover topics such as Ethereum, globally traded commodities, airports, flight routes, and a reading list of books, because the generating process for each of these datasets is different. It will be interesting to visualize and analyze the datasets.
Hopefully, the experience that we will gain over the course of this book will help us in becoming effective at using Superset for data visualization and dashboarding.
Installing Superset
Let's get started by making a Superset web app server. We will cover security, user roles, and permissions for the web app in the next chapter.
Instead of a local machine, one can also choose to set up Superset in the cloud. This way, we can even share our Superset web app with authenticated users via an internet browser (for example, Firefox or Chrome).
We will be using Google Compute Engine (GCE) for the Superset server. You can use the link https://console.cloud.google.com and set up your account.
After you have set up your account, go to the URL https://console.cloud.google.com/apis/credentials/serviceaccountkey to download a file, `<project_id>.json`. Save this somewhere safe. This is the Google Cloud authorization JSON key file. We will copy the contents of this file to our GCE instance after we launch it. Superset uses the information in this file to authenticate itself to Google BigQuery.
GCE instances are very easy to configure and launch. Anyone with a Google account can use it. After logging in to you Google account, use this URL: https://console.cloud.google.com/compute/instances. Here, launch a g1-small (1 vCPU, 1.7 GB memory) instance with default settings. When we have to set up Superset for a large number of concurrent users (greater than five), we should choose higher compute power instances.
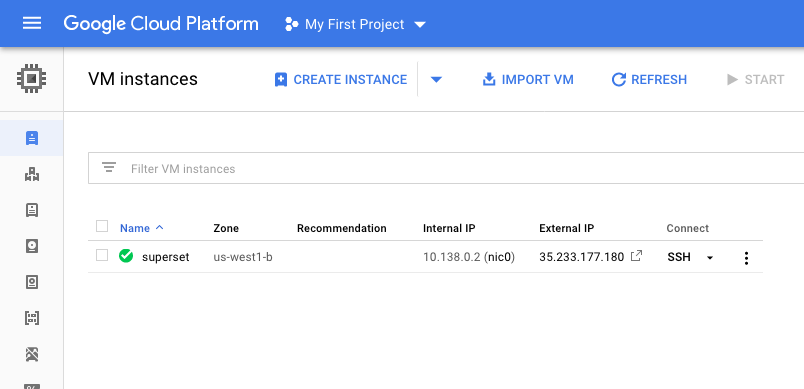
After launching, on the VM instances screen we can see our g1-small GCE instance is up and running:
Sharing Superset
We will need to share our Superset web app with others, and for that we will have to figure out the URL users can use to access it through their internet browsers.
The standard format of a web server URL is http://{address}:{port number}.
The default port for Superset is 8088. On a locally run Superset web app server, the address is localhost. Servers on internal networks are available on their internal IP address. Web apps on cloud services such as GCE or Amazon Elastic Compute have the machine's external IP as the address.
On GCE's VM instances screen, an external IP is displayed for each instance that is started. A new external IP is generated for every new instance. In the following screenshot, the external IP specified is 35.233.177.180. To share the server with registered users on the internet, we make a note of the external IP on our own screens:

To allow users to access the port, we need to go to VPC network | Firewall rules and Create a firewall rule that will open port 8088 for users. We can use the field values shown in the following screenshot for the rule:

Now, we are ready to install Superset!
Before we proceed, use the ssh option to open a Terminal that is connected to the GCE instance while staying inside your browser. This is one of the many amazing features of GCE.
In the Terminal, we will run some commands to install the dependencies and configure Superset for our first dashboard:
# 1) Install os-level dependencies
sudo apt-get install build-essential libssl-dev libffi-dev python-dev python-pip libsasl2-dev libldap2-dev
# 2) Check for Python 2.7
python --version
# 3) Install pip
wget https://bootstrap.pypa.io/get-pip.py
sudo python get-pip.py
# 4) Install virtualenv
sudo pip install --upgrade virtualenv
# 5) Install virtualenvironment manager
sudo pip install virtualenvwrapper
source /usr/local/bin/virtualenvwrapper.sh
echo 'source /usr/local/bin/virtualenvwrapper.sh' >> ~/.bash_profile
# 6) Make virtual environment
mkvirtualenv supervenv
# 7) Install superset and virtualenv in the new virtual environment
(supervenv) pip install superset
(supervenv) pip install virtualenv virtualenvwrapper
# 8) Install database connector
(supervenv) pip install pybigquery
# 9) Create and open an authentication file for BigQuery
(supervenv) vim ~/.google_cdp_key.json
# 10) Copy and paste the contents of <project_id>.json key file to ~/.google_cdp_key.json
# 11) Load the new authentication file
(supervenv) echo 'export GOOGLE_APPLICATION_CREDENTIALS="$HOME/.google_cdp_key.json"' >> ~/.bash_profile
(supervenv) source ~/.bash_profile
Configuring Superset
Superset uses the Flask-AppBuilder framework (fabmanager) to store and manage data for authentication, user permissions, and user roles in Superset.
After installing fabmanager in the Python virtual environment, we use the create-admin command in fabmanager and specify Superset as the app. The Flask-AppBuilder framework will create a metadata database using SQLite by default in the ~/.superset location:
# On the Terminal to setup FlaskAppBuilder for superset on GCE
# Create an admin user (you will be prompted to set username, first and last name before setting a password) (supervenv) fabmanager create-admin --app superset
After creating the admin user for the Superset app, we have to run the following commands to create tables and update columns in the metadata database:
# Initialize the database (supervenv) superset db upgrade
# Creates default roles and permissions
(supervenv) superset init
We can do a sanity check to verify that the metadata database has been created in the expected location. For this, we install sqlite3 to query the SQLite metadata database:
# Install sqlite3
(superenv) sudo apt-get install sqlite3
# Navigate to the home directory
(supervenv) cd ~/.superset
# Verify database is created
(supervenv) sqlite3
> .open superset.db
> .tables
sqlite> .tables
ab_permission annotation_layer logs
ab_permission_view clusters metrics
ab_permission_view_role columns query
ab_register_user css_templates saved_query
ab_role dashboard_slices slice_user
ab_user dashboard_user slices
ab_user_role dashboards sql_metrics
ab_view_menu datasources table_columns
access_request dbs tables
alembic_version favstar url
annotation keyvalue
Finally, let's start the Superset web server:
# run superset webserver
(supervenv) superset runserver
Go to http://<your_machines_external_ip>:8088 in your Chrome or Firefox web browser. The external IP I used is the one specified for the GCE instance I am using. Open the web app in your browser and log in with the admin credentials you entered when using the create-admin command on fabmanager.
After the login screen, you will see the welcome screen of your Superset web app:
Adding a database
The navigation bar lists all the features. The Sources section is where you will create and maintain database integrations and configure table schemas to use as sources of data.
Any SQL database that has a SQLAlchemy connector such as PostgreSQL, MySQL, SQLite, MongoDB, and Snowflake can work with Superset.
Depending on the databases that we connect to Superset, the corresponding SQLAlchemy connectors have to be installed:
|
Database
|
PyPI package
|
|
MySQL
|
mysqlclient
|
|
PostgreSQL
|
psycopg2
|
|
Presto
|
pyhive
|
|
Hive
|
pyhive
|
|
Oracle
|
cx_oracle
|
|
SQLite
|
Included in Superset
|
|
Snowflake
|
snowflake-sqlalchemy
|
|
Redshift
|
sqlalchemy-redshift
|
|
MS SQL
|
pymssql
|
|
Impala
|
impyla
|
|
Spark SQL
|
pyhive
|
|
Greenplum
|
psycopg2
|
|
Athena
|
PyAthenaJDBC>1.0.9
|
|
Vertica
|
sqlalchemy-vertica-python
|
|
ClickHouse
|
sqlalchemy-clickhouse
|
|
Kylin
|
kylinpy
|
|
BigQuery
|
pybigquery
|
It is recommended that you use a database that supports the creation of views. When columns from more than one table have to be fetched for visualization, views of those joins can be created in the database and visualized on Superset, because table joins are not supported in Superset.
SQL query execution for fetching data and rendering visualizations is done at the database level, and Superset only fetches results afterwards. A database with a query execution engine that scales with your data will make your dashboard more real time.
In this book, we will work with public datasets available in Google BigQuery. We have already installed a connector for BigQuery in our installation routine, using the pip install pybigquery command. We have set up authentication for BigQuery using a key file. You should verify that, by confirming that the environment variable points to the valid key file:
echo $GOOGLE_APPLICATION_CREDENTIALS
# It should return
> /home/<your user name>/.google_cdp_key.json
Now, let's add BigQuery as a database in three steps:
- Select the Databases option from the drop-down list and create (+) your first database
- Set Database to superset-bigquery and SQLAlchemy URI to bigquery://
- Save the database
You can verify the database connection by clicking on the Test Connection button; it should return Seems OK! as follows:

Adding a table
We will add the questions table from the Stack Overflow public dataset at https://cloud.google.com/bigquery/public-data/stackoverflow in three steps:
- Select the Tables option from the drop-down list, and create your first table
- Set values in Database to superset-bigquery and Table Name to bigquery-public-data.stackoverflow.posts_questions
- Save the table:

Creating a visualization
That was smooth! You were able to add your first database and table to Superset. Now, it's time for the fun part, which is visualizing and analyzing the data. In Table, we will find the bigquery-public-data.stackoverflow.posts_questions listed as follows:

When you click on it, it will take you to the chart UI:

Here, we will make a time series plot of the number of questions posted by year. In the Data tab, the Time section is used to restrict data by a temporal column value. We do not want to restrict data for the time series plot. We can clear the Since field.
In order to add axis labels to the line chart, select the Style tab and add descriptions in the X Axis Label and Y Axis Label fields:

Set year as Time Grain and COUNT(*) as the Metrics. Finally, hit Run Query:

We have our first visualization! We can see how the number of questions grew quickly from 2008-2013. Now, Save the visualization, so that we can add it to our dashboard later:

Uploading a CSV
In many types of analytical work, data is available in CSV or Excel files and not in a database. You can use the Upload a CSV feature to upload CSVs as tables in Superset, without parent database integration.
We will get some real data to test this. Let's download the Ethereum transaction history from http://etherscan.io and create a new table:
curl https://etherscan.io/chart/tx?output=csv > /tmp/eth_txn.csv
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 35279 0 35279 0 0 98k 0 --:--:-- --:--:-- --:--:-- 98k
# create a sqlite database to store the csv
cd ~/.superset
# this will create a sqlite database, quit after it opens the console
sqlite3 upload_csv.db

Once you have created the upload_csv database integration, make sure you select it when you are uploading the .csv file, as shown in the following screenshot:

Configuring the table schema
The List Columns tab on the Edit Table form lets you configure the Column attributes:

Customizing the visualization
The Ethereum dataset has a Date (UTC) column, a UnixTimestamp column, and a value representing the total transaction volume in USD on that date. Let's chart the Value column in the latest Ethereum transaction history data:

The Data form calculates the sum of transactions grouped by dates. There is only one value over which the SUM(Value) aggregate function is computed:

The sum of transaction values, grouped by the Date column value and sorted in descending order, shows that the busiest days in the Ethereum network are also the most recent.
Making a dashboard
Making a dashboard in Superset is quick and easy. Just go to Dashboards and create a new dashboard. In the form, fill in the Title and a string value in the Slug field, which will be used to create the dashboard's URL, and hit Save:

Open the dashboard and select the Edit Dashboard option. Because we have two seemingly unrelated datasets, we can use the Tabs dashboard component to see them one at a time:

Once you have added a Tabs component, insert the two charts you just made using the Your charts & filters option:

The dashboard URL syntax is http://{address}:{port number}/superset/dashboard/getting-started. Replace the address and port number variables with the appropriate values, and you can use this link to open or share your dashboard.
Our dashboard is ready and live for users with accounts on the web server. In the next chapter, we will learn about user roles. After that, you will able to get your favorite collaborators to register. With them on board, you can start collaborating on charts and dashboards for your data analysis projects.
Summary
That must have felt productive, since we were able to create our dashboard from nothing in Superset.
Before we summarize what we have just finished in this chapter, it is important that we discuss when Superset might not be the right visualization tool for a data analysis project.
Visualization of data requires data aggregation. Data aggregation is a function of one or more column values in tables. A group by operation is applied on a particular column to create groups of observations, which are then replaced with the summary statistics defined by the data aggregation function. Superset provides many data aggregation functions; however, it has limited usability when hierarchical data aggregation is required for visualizations.
Hierarchical data aggregation is the process of taking a large amount of rows in a table and displaying summaries of partitions and their sub-partitions. This is not an option in Superset for most of the visualizations.
Also, Superset has limited customization options on the design and formatting of visualizations. It supports changes in color schemes and axis label formatting. Individuals or teams who want to tinker and optimize the visual representation of their data will find Superset very limited for their needs.
Finally, it's time to summarize our achievements. We have been able to install Superset, add a database, create a dashboard, and share it with users. We are now ready to add additional databases and tables, and create new visualizations and dashboards. Exploring data and telling data stories with Superset dashboards is one of your skill sets now!




