


















 Download code from GitHub
Download code from GitHub
Hadoop 3.0 - Background and Introduction
The world is evolving day by day, from automated call assistance to smart devices taking intelligent decisions, to self-driven decision-making cars to humanoid robots, all driven by processing large amount of data and analyzing it. We are rapidly approaching to the new era of data age. The IDC whitepaper (https://www.seagate.com/www-content/our-story/trends/files/Seagate-WP-DataAge2025-March-2017.pdf) on data evolution published in 2017 predicts data volumes to reach 163 zettabytes (1 zettabyte = 1 trillion terabytes) by the year 2025. This will involve digitization of all the analog data that we see between now and then. This flood of data will come from a broad variety of different device types, including IoT devices (sensor data) from industrial plants as well as home devices, smart meters, social media, wearables, mobile phones, and so on.
In our day-to-day life, we have seen ourselves participating in this evolution. For example, I started using a mobile phone in 2000 and, at that time, it had basic functions such as calls, torch, radio, and SMS. My phone could barely generate any data as such. Today, I use a 4G LTE smartphone capable of transmitting GBs of data including my photos, navigation history, and my health parameters from my smartwatch, on different devices over the internet. This data is effectively being utilized to make smart decisions.
Let's look at some real-world examples of big data:
- Companies such as Facebook and Instagram are using face recognition tools to identify photos, classify them, and bring you friend suggestions by comparison
- Companies such as Google and Amazon are looking at human behavior based on navigation patterns and location data, providing automated recommendations for shopping
- Many government organizations are analyzing information from CCTV cameras, social media feeds, network traffic, phone data, and bookings to trace criminals and predict potential threats and terrorist attacks
- Companies are using sentiment analysis from message posts and tweets to improve the quality of their products, as well as brand equities, and have targeted business growth
- Every minute, we send 204 million emails, view 20 million photos on Flickr, perform 2 million searches on Google, and generate 1.8 million likes on Facebook (Source)
With this data growth, the demands to process, store, and analyze data in a faster and scalable manner will arise. So, the question is: are we ready to accommodate these demands? Year after year, computer systems have evolved and so has storage media in terms of capacities; however, the capability to read-write byte data is yet to catch up with these demands. Similarly, data coming from various sources and various forms needs to be correlated together to make meaningful information. For example, with a combination of my mobile phone location information, billing information, and credit card details, someone can derive my interests in food, social status, and financial strength. The good part is that we see a lot of potential of working with big data. Today, companies are barely scratching the surface; however, we are still struggling to deal with storage and processing problems unfortunately.
This chapter is intended to provide the necessary background for you to get started on Apache Hadoop. It will cover the following key topics:
- How it all started
- What Apache Hadoop is and why it is important
- How Apache Hadoop works
- Hadoop 3.0 releases and new features
- Choosing the right Hadoop distribution
How it all started
In the early 2000s, search engines on the World Wide Web were competing to bring improved and accurate results. One of the key challenges was about indexing this large data, keeping a limit over the cost factor on hardware. Doug Cutting and Mike Caferella started development on Nutch in 2002, which would include a search engine and web crawler. However, the biggest challenge was to index billions of pages due to lack of matured cluster management systems. In 2003, Google published a research paper on Google's distributed filesystem (GFS) (https://ai.google/research/pubs/pub51). This helped them devise a distributed filesystem for Nutch called NDFS. In 2004, Google introduced MapReduce programming to the world. The concept of MapReduce was inspired from the Lisp programming language. In 2006, Hadoop was created under the Lucene umbrella. In the same year, Doug was employed by Yahoo to solve some of the most challenging issues with Yahoo Search, which was barely surviving. The following is a timeline of these and later events:
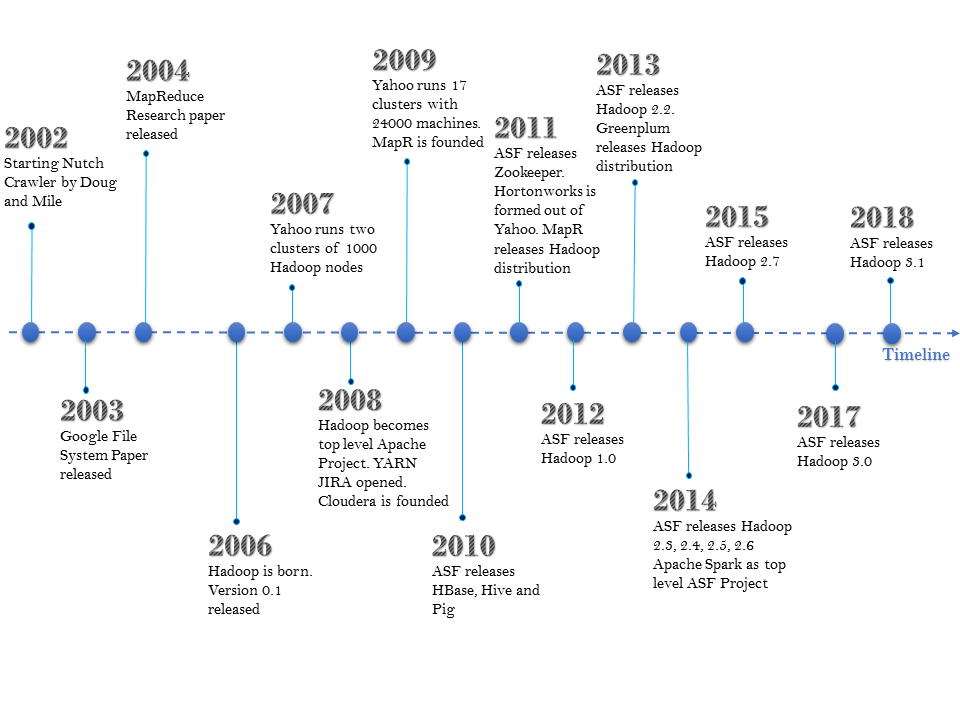
In 2007, many companies such as LinkedIn, Twitter, and Facebook started working on this platform, whereas Yahoo's production Hadoop cluster reached the 1,000-node mark. In 2008, Apache Software Foundation (ASF) moved Hadoop out of Lucene and graduated it as a top-level project. This was the time when the first Hadoop-based commercial system integration company, called Cloudera, was formed.
In 2009, AWS started giving MapReduce hosting capabilities, whereas Yahoo achieved the 24k nodes production cluster mark. This was the year when another SI (System Integrator) called MapR was founded. In 2010, ASF released HBase, Hive, and Pig to the world. In the year 2011, the road ahead for Yahoo looked difficult, so original Hadoop developers from Yahoo separated from it, and formed a company called Hortonworks. Hortonworks offers 100% open source implementation of Hadoop. The same team also become part of the Project Management Committee of ASF.
In 2012, ASF released the first major release of Hadoop 1.0, and immediately next year, it released Hadoop 2.X. In subsequent years, the Apache open source community continued with minor releases of Hadoop due to its dedicated, diverse community of developers. In 2017, ASF released Apache Hadoop version 3.0. On similar lines, companies such as Hortonworks, Cloudera, MapR, and Greenplum are also engaged in providing their own distribution of the Apache Hadoop ecosystem.
What Hadoop is and why it is important
The Apache Hadoop is a collection of open source software that enables distributed storage and processing of large datasets across a cluster of different types of computer systems. The Apache Hadoop framework consists of the following four key modules:
- Apache Hadoop Common
- Apache Hadoop Distributed File System (HDFS)
- Apache Hadoop MapReduce
- Apache Hadoop YARN (Yet Another Resource Manager)
Each of these modules covers different capabilities of the Hadoop framework. The following diagram depicts their positioning in terms of applicability for Hadoop 3.X releases:
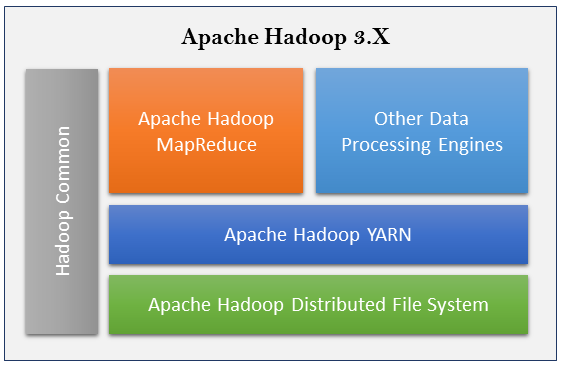
Apache Hadoop Common consists of shared libraries that are consumed across all other modules including key management, generic I/O packages, libraries for metric collection, and utilities for registry, security, and streaming. Apache HDFS provides highly tolerant distributed filesystem across clustered computers.
Apache Hadoop provides a distributed data processing framework for large datasets using a simple programming model called MapReduce. A programming task that is divided into multiple identical subtasks and that is distributed among multiple machines for processing is called a map task. The results of these map tasks are combined together into one or many reduce tasks. Overall, this approach of computing tasks is called the MapReduce Approach. The MapReduce programming paradigm forms the heart of the Apache Hadoop framework, and any application that is deployed on this framework must comply to MapReduce programming. Each task is divided into a mapper task, followed by a reducer task. The following diagram demonstrates how MapReduce uses the divide-and-conquer methodology to solve its complex problem using a simplified methodology:
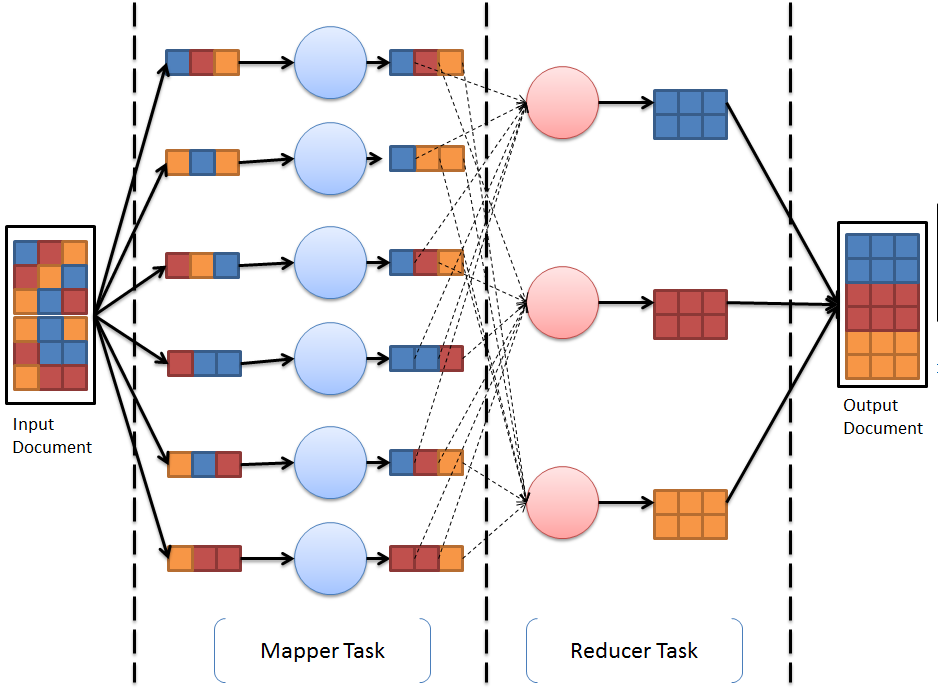
Apache Hadoop MapReduce provides a framework to write applications to process large amounts of data in parallel on Hadoop clusters in a reliable manner. The following diagram describes the placement of multiple layers of the Hadoop framework. Apache Hadoop YARN provides a new runtime for MapReduce (also called MapReduce 2) for running distributed applications across clusters. This module was introduced in Hadoop version 2 onward. We will be discussing these modules further in later chapters. Together, these components provide a base platform to build and compute applications from scratch. To speed up the overall application building experience and to provide efficient mechanisms for large data processing, storage, and analytics, the Apache Hadoop ecosystem comprises additional software. We will cover these in the last section of this chapter.
Now that we have given a quick overview of the Apache Hadoop framework, let's understand why Hadoop-based systems are needed in the real world.
Apache Hadoop was invented to solve large data problems that no existing system or commercial software could solve. With the help of Apache Hadoop, the data that used to get archived on tape backups or was lost is now being utilized in the system. This data offers immense opportunities to provide insights in history and to predict the best course of action. Hadoop is targeted to solve problems involving the four Vs (Volume, Variety, Velocity, and Veracity) of data. The following diagram shows key differentiators of why Apache Hadoop is useful for business:
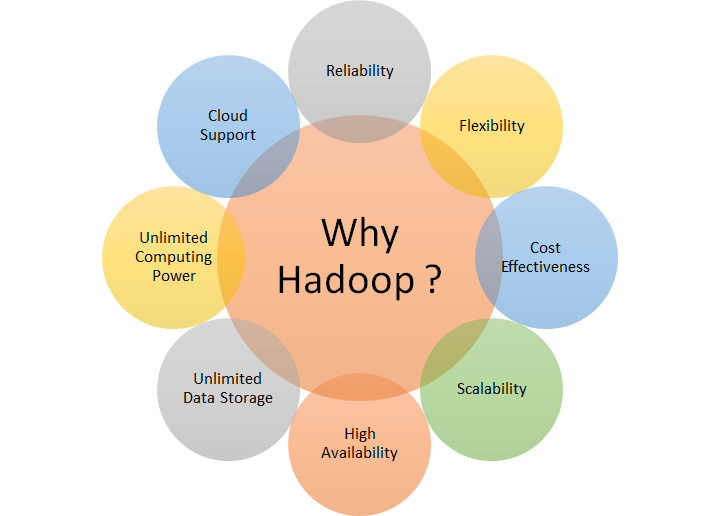
Let's go through each of the differentiators:
- Reliability: The Apache Hadoop distributed filesystem offers replication of data, with a default replication of 3x. This ensures that there is no data loss despite failure of cluster nodes.
- Flexibility: Most of the data that users today must deal with is unstructured. Traditionally, this data goes unnoticed; however, with Apache Hadoop, variety of data including structured and unstructured data can be processed, stored, and analyzed to make better future decisions. Hadoop offers complete flexibility to work across any type of data.
- Cost effectiveness: Apache Hadoop is completely open source; it comes for free. Unlike traditional software, it can run on any hardware or commodity systems and it does not require high-end servers; the overall investment and total cost of ownership of building a Hadoop cluster is much less than the traditional high-end system required to process data of the same scale.
- Scalability: Hadoop is a completely distributed system. With data growth, implementation of Hadoop clusters can add more nodes dynamically or even downsize them based on data processing and storage demands.
- High availability: With data replication and massively parallel computation running on multi-node commodity hardware, applications running on top of Hadoop provide high availability environment for all implementations.
- Unlimited storage space: Storage in Hadoop can scale up to petabytes of data storage with HDFS. HDFS can store any type of data of larger size in a completely distributed manner. This capability enables Hadoop to solve large data problems.
- Unlimited computing power: Hadoop 3.x onward supports more than 10,000 nodes of Hadoop clusters, whereas Hadoop 2.x supports up to 10,000 node clusters. With such a massive parallel processing capability, Apache Hadoop offers unlimited computing power to all applications.
- Cloud support: Today, almost all cloud providers support Hadoop directly as a service, which means a completely automated Hadoop setup is available on demand. It supports dynamic scaling too; overall it becomes an attractive model due to the reduced Total Cost of Ownership (TCO).
Now is the time to do a deep dive into how Apache Hadoop works.
How Apache Hadoop works
The Apache Hadoop framework works on a cluster of nodes. These nodes can be either virtual machines or physical servers. The Hadoop framework is designed to work seamlessly on all types of these systems. The core of Apache Hadoop is based on Java. Each of the components in the Apache Hadoop framework performs different operations. Apache Hadoop is comprised of the following key modules, which work across HDFS, MapReduce, and YARN to provide a truly distributed experience to the applications. The following diagram shows the overall big picture of the Apache Hadoop cluster with key components:

Let's go over the following key components and understand what role they play in the overall architecture:
- Resource Manager
- Node Manager
- YARN Timeline Service
- NameNode
- DataNode
Resource Manager
Resource Manager is a key component in the YARN ecosystem. It was introduced in Hadoop 2.X, replacing JobTracker (MapReduce version 1.X). There is one Resource Manager per cluster. Resource Manager knows the location of all slaves in the cluster and their resources, which includes information such as GPUs (Hadoop 3.X), CPU, and memory that is needed for execution of an application. Resource Manager acts as a proxy between the client and all other Hadoop nodes. The following diagram depicts the overall capabilities of Resource Manager:

YARN resource manager handles all RPC such as services that allow clients to submit their jobs for execution and obtain information about clusters and queues and termination of jobs. In addition to regular client requests, it provides separate administration services, which get priorities over normal services. Similarly, it also keeps track of available resources and heartbeats from Hadoop nodes. Resource Manager communicates with Application Masters to manage registration/termination of an Application Master, as well as checking health. Resource Manager can be communicated through the following mechanisms:
- RESTful APIs
- User interface (New Web UI)
- Command-line interface (CLI)
These APIs provide information such as cluster health, performance index on a cluster, and application-specific information. Application Manager is the primary interacting point for managing all submitted applications. YARN Schedule is primarily used to schedule jobs with different strategies. It supports strategies such as capacity scheduling and fair scheduling for running applications. Another new feature of resource manager is to provide a fail-over with near zero downtime for all users. We will be looking at more details on resource manager in Chapter 5, Building Rich YARN Applications on YARN.
Node Manager
As the name suggests, Node Manager runs on each of the Hadoop slave nodes participating in the cluster. This means that there could many Node Managers present in a cluster when that cluster is running with several nodes. The following diagram depicts key functions performed by Node Manager:
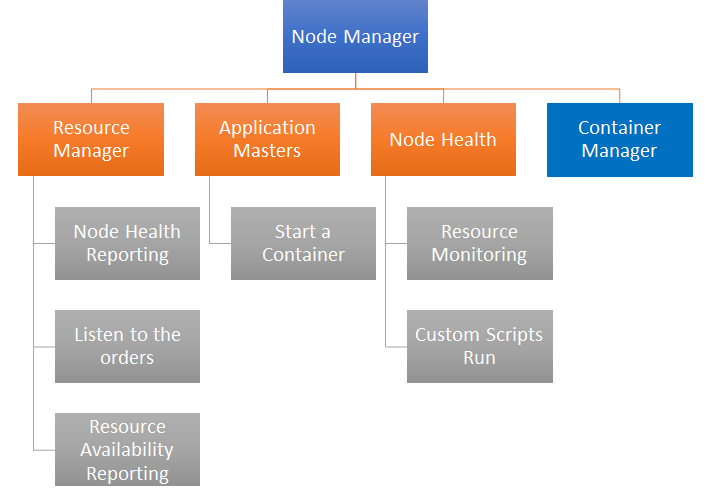
Node Manager runs different services to determine and share the health of the node. If any services fail to run on a node, Node Manager marks it as unhealthy and reports it back to resource manager. In addition to managing the life cycles of nodes, it also looks at available resources, which include memory and CPU. On startup, Node Manager registers itself to resource manager and sends information about resource availability. One of the key responsibilities of Node Manager is to manage containers running on a node through its Container Manager. These activities involve starting a new container when a request is received from Application Master and logging the operations performed on container. It also keeps tabs on the health of the node.
Application Master is responsible for running one single application. It is initiated based on the new application submitted to a Hadoop cluster. When a request to execute an application is received, it demands container availability from resource manager to execute a specific program. Application Master is aware of execution logic and it is usually specific for frameworks. For example, Apache Hadoop MapReduce has its own implementation of Application Master.
YARN Timeline Service version 2
This service is responsible for collecting different metric data through its timeline collectors, which run in a distributed manner across Hadoop cluster. This collected information is then written back to storage. These collectors exist along with Application Masters—one per application. Similar to Application Manager, resource managers also utilize these timeline collectors to log metric information in the system. YARN Timeline Server version 2.X provides a RESTful API service to allow users to run queries for getting insights on this data. It supports aggregation of information. Timeline Server V2 utilizes Apache HBase as storage for these metrics by default, however, users can choose to change it.
NameNode
NameNode is the gatekeeper for all HDFS-related queries. It serves as a single point for all types of coordination on HDFS data, which is distributed across multiple nodes. NameNode works as a registry to maintain data blocks that are spread across Data Nodes in the cluster. Similarly, the secondary NameNodes keep a backup of active Name Node data periodically (typically every four hours). In addition to maintaining the data blocks, NameNode also maintains the health of each DataNode through the heartbeat mechanism. In any given Hadoop cluster, there can only be one active name node at a time. When an active NameNode goes down, the secondary NameNode takes up responsibility. A filesystem in HDFS is inspired from Unix-like filesystem data structures. Any request to create, edit, or delete HDFS files first gets recorded in journal nodes; journal nodes are responsible for coordinating with data nodes for propagating changes. Once the writing is complete, changes are flushed and a response is sent back to calling APIs. In case the flushing of changes in the journal files fails, the NameNode moves on to another node to record changes.
DataNode
DataNode in the Hadoop ecosystem is primarily responsible for storing application data in distributed and replicated form. It acts as a slave in the system and is controlled by NameNode. Each disk in the Hadoop system is divided into multiple blocks, just like a traditional computer storage device. A block is a minimal unit in which the data can be read or written by the Hadoop filesystem. This ecosystem gives a natural advantage in slicing large files into these blocks and storing them across multiple nodes. The default block size of data node varies from 64 MB to 128 MB, depending upon Hadoop implementation. This can be changed through the configuration of data node. HDFS is designed to support very large file sizes and for write-once-read-many-based semantics.
Data nodes are primarily responsible for storing and retrieving these blocks when they are requested by consumers through Name Node. In Hadoop version 3.X, DataNode not only stores the data in blocks, but also the checksum or parity of the original blocks in a distributed manner. DataNodes follow the replication pipeline mechanism to store data in chunks propagating portions to other data nodes.
When a cluster starts, NameNode starts in a safe mode, until the data nodes register the data block information with NameNode. Once this is validated, it starts engaging with clients for serving the requests. When a data node starts, it first connects with Name Node, reporting all of the information about its data blocks' availability. This information is registered in NameNode, and when a client requests information about a certain block, NameNode points to the respective data not from its registry. The client then interacts with DataNode directly to read/write the data block. During the cluster processing, data node communicates with name node periodically, sending a heartbeat signal. The frequency of the heartbeat can be configured through configuration files.
We have gone through different key architecture components of the Apache Hadoop framework; we will be getting a deeper understanding in each of these areas in the next chapters.
Hadoop 3.0 releases and new features
Apache Hadoop development is happening on multiple tracks. The releases of 2.X, 3.0.X, and 3.1.X were simultaneous. Hadoop 3.X was separated from Hadoop 2.x six years ago. We will look at major improvements in the latest releases: 3.X and 2.X. In Hadoop version 3.0, each area has seen a major overhaul, as can be seen in the following quick overview:
- HDFS benefited from the following:
- Erasure code
- Multiple secondary Name Node support
- Intra-Data Node Balancer
- Improvements to YARN include the following:
- Improved support for long-running services
- Docker support and isolation
- Enhancements in the Scheduler
- Application Timeline Service v.2
- A new User Interface for YARN
- YARN Federation
- MapReduce received the following overhaul:
- Task-level native optimization
- Feature to device heap-size automatically
- Overall feature enhancements include the following:
- Migration to JDK 8
- Changes in hosted ports
- Classpath Isolation
- Shell script rewrite and ShellDoc
Erasure Code (EC) is a one of the major features of the Hadoop 3.X release. It changes the way HDFS stores data blocks. In earlier implementations, the replication of data blocks was achieved by creating replicas of blocks on different node. For a file of 192 MB with a HDFS block size of 64 MB, the old HDFS would create three blocks and, if a cluster has a replication of three, it would require the cluster to store nine different blocks of data—576 MB. So the overhead becomes 200%, additional to the original 192 MB. In the case of EC, instead of replicating the data blocks, it creates parity blocks. In this case, for three blocks of data, the system would create two parity blocks, resulting in a total of 320 MB, which is approximately 66.67% overhead. Although EC achieves significant gain on data storage, it requires additional computing to recover data blocks in case of corruption, slowing down recovery with respect to the traditional way in old Hadoop versions.
We have already seen multiple secondary Name Node support in the architecture section. Intra-Data Node Balancer is used to balance skewed data resulting from the addition or replacement of disks among Hadoop slave nodes. This balancer can be explicitly called from the HDFS shell asynchronously. This can be used when new nodes are added to the system.
In Hadoop v3, YARN Scheduler has been improved in terms of its scheduling strategies and prioritization between queues and applications. Scheduling can be performed among the most eligible nodes rather than one node at a time, driven by heartbeat reporting, as in older versions. YARN is being enhanced with abstract framework to support long-running services; it provides features to manage the life cycle of these services and support upgrades, resizing containers dynamically rather than statically. Another major enhancement is the release of Application Timeline Service v2. This service now supports multiple instances of readers and writes (compared to single instances in older Hadoop versions) with pluggable storage options. The overall metric computation can be done in real time, and it can perform aggregations on collected information. The RESTful APIs are also enhanced to support queries for metric data. YARN User Interface is enhanced significantly, for example, to show better statistics and more information, such as queue. We will be looking at it in Chapter 5, Building Rich YARN Applications and Chapter 6, Monitoring and Administration of a Hadoop Cluster.
Hadoop version 3 and above allows developers to define new resource types (earlier there were only two managed resources: CPU and memory). This enables applications to consider GPUs and disks as resources too. There have been new proposals to allow static resources such as hardware profiles and software versions to be part of the resourcing. Docker has been one of the most successful container applications that the world has adapted rapidly. In Hadoop version 3.0 onward, the experimental/alpha dockerization of YARN tasks is now made part of standard features. So, YARN can be deployed in dockerized containers, giving a complete isolation of tasks. Similarly, MapReduce Tasks are optimized (https://issues.apache.org/jira/browse/MAPREDUCE-2841) further with native implementation of Map output collector for activities such as sort and spill. This enhancement is intended to improve the performance of MapReduce tasks by two to three times.
YARN Federation is a new feature that enables YARN to scale over 100,000 of nodes. This feature allows a very large cluster to be divided into multiple sub-clusters, each running YARN Resource Manager and computations. YARN Federation will bring all these clusters together, making them appear as a single large YARN cluster to the applications. More information about YARN Federation can be obtained from this source.
Another interesting enhancement is migration to newer JDK 8. Here is the supportability matrix for previous and new Hadoop versions and JDK:
| Releases | Supported JDK |
| Hadoop 2.6.X | JDK 6 onward |
| Hadoop 2.7.X/2.8.X/2.9.X | JDK 7 onward |
| Hadoop 3.X | JDK 8 onward |
Earlier, applications often had conflicts due to the single JAR file; however, the new release has two separate jar libraries: server side and client side. This achieves isolation of classpaths between server and client jars. The filesystem is being enhanced to support various types of storage such as Amazon S3, Azure Data Lake storage, and OpenStack Swift storage. Hadoop Command-line interface has been renewed and so are the daemons/processes to start, stop, and configure clusters. With older Hadoop (version 2.X), the heap size for Java and other tasks was required to be set through the map/reduce.java.opts and map/reduce.memory.mb properties. With Hadoop version 3.X, the heap size is derived automatically. All of the default ports used for NameNode, DataNode, and so forth are changed. We will be looking at new ports in the next chapter. In Hadoop 3, the shell scripts are rewritten completely to address some long-standing defects. The new enhancement allows users to add build directories to classpaths; the command to change permissions and the owner of HDFS folder structure will be done as a MapReduce job.
Choosing the right Hadoop distribution
We have seen the evolution of Hadoop from a simple lab experiment tool to one of the most famous projects of Apache Software Foundation in the previous section. When the evolution started, many commercial implementations of Hadoop spawned. Today, we see more than 10 different implementations that exist in the market (Source). There is a debate about whether to go with full open source-based Hadoop or with a commercial Hadoop implementation. Each approach has its pros and cons. Let's look at the open source approach.
Pros of open source-based Hadoop include the following:
- With a complete open source approach, you can take full advantage of community releases.
- It's easier and faster to reach customers due to software being free. It also reduces the initial cost of investment.
- Open source Hadoop supports open standards, making it easy to integrate with any system.
Cons of open source-based Hadoop include the following:
- In the complete open source Hadoop scenario, it takes longer to build implementations compared to commercial software, due to lack of handy tools that speed up implementation
- Supporting customers and fixing issues can become a tedious job due to the chaotic nature of the open source community
- The roadmap of the product cannot be controlled/ginfluenced based on business needs
Given these challenges, many times, companies prefer to go with commercial implementations of Apache Hadoop. We will cover some of the key Hadoop distributions in this section.
Cloudera Hadoop distribution
Cloudera is well known and one of the oldest big data implementation players in the market. They have done first commercial releases of Hadoop in the past. Along with a Hadoop core distribution called CDH, Cloudera today provides many innovative tools such as proprietary Cloudera Manager to administer, monitor, and manage the Cloudera platform; Cloudera Director to easily deploy Cloudera clusters across the cloud; Cloudera Data Science Workbench to analyze large data and create statistical models out of it; and Cloudera Navigator to provide governance on the Cloudera platform. Besides ready-to-use products, it also provides services such as training and support. Cloudera follows separate versioning for its CDH; the latest CDH (5.14) uses Apache Hadoop 2.6.
Pros of Cloudera include the following:
- Cloudera comes with many tools that can help speed up the overall cluster creation process
- Cloudera-based Hadoop distribution is one of the most mature implementations of Hadoop so far
- The Cloudera User Interface and features such as the dashboard management and wizard-based deployment offer an excellent support system while implementing and monitoring Hadoop clusters
- Cloudera is focusing beyond Hadoop; it has brought in a new era of enterprise data hubs, along with many other tools that can handle much more complex business scenarios instead of just focusing on Hadoop distributions
Cons of Cloudera include the following:
- Cloudera distribution is not completely open source; there are proprietary components that require users to use commercial licenses. Cloudera offers a limited 60-day trial license.
Hortonworks Hadoop distribution
Hortonworks, although late in the game (founded in 2011), has quickly emerged as a leading vendor in the big data market. Hortonworks was started by Yahoo engineers. The biggest differentiator between Hortonworks and other Hadoop distributions is that Hortonworks is the only commercial vendor to offer its enterprise Hadoop distribution completely free and 100% open source. Unlike Cloudera, Hortonworks focuses on embedding Hadoop in existing data platforms. Hortonworks has two major product releases. Hortonworks Data Platform (HDP) provides an enterprise-grade open source Apache Hadoop distribution, while Hortonworks Data Flow (HDF) provides the only end-to-end platform that collects, curates, analyzes, and acts on data in real time and on-premises or in the cloud, with a drag-and-drop visual interface. In addition to products, Hortonworks also provides services such as training, consultancy, and support through its partner network. Now, let's look at its pros and cons.
Pros of the Hortonworks Hadoop distribution include the following:
- 100% open source-based enterprise Hadoop implementation with commercial license need
- Hortonworks provides additional open source-based tools to monitor and administer clusters
Cons of the Hortonworks Hadoop distribution include the following:
- As a business strategy, Hortonworks has focused on developing the platform layer so, for customers planning to utilize Hortonworks clusters, the cost to build capabilities is higher
MapR Hadoop distribution
MapR is one of the initial companies that started working on their own Hadoop distribution. When it comes to a Hadoop distribution, MapR has gone one step further and replaced HDFS of Hadoop with its own proprietary filesystem called MapRFS. MapRFS is a filesystem that supports enterprise-grade features such as better data management, fault tolerance, and ease of use. One key differentiator between HDFS and MapRFS is that MapRFS allows random writes on its filesystem. Additionally, unlike HDFS, it can be mounted locally through NFS to any filesystem. MapR implements POSIX (HDFS has POSIX-like implementation), so any Linux developer can apply their knowledge to run different commands seamlessly. MapR-like filesystems can be utilized for OLTP-like business requirements due to its unique features.
Pros of the MapR Hadoop distribution include the following:
- It's the only Hadoop distribution without Java dependencies (as MapR is based on C)
- Offers excellent and production-ready Hadoop clusters
- MapRFS is easy to use and it provides multi-node FS access on a local NFS mounted
Cons of the MapR Hadoop distribution include the following:
- It gets more and more proprietary instead of open source. Many companies are looking for vendor-free development, so MapR does not fit there.
Each of the distributions, including open source, that we covered have unique business strategy and features. Choosing the right Hadoop distribution for a problem is driven by multiple factors such as the following:
- What kind of application needs to be addressed by Hadoop
- The type of application—transactional or analytical—and what are the key data processing requirements
- Investments and the timeline of project implementation
- Support and training requirements of a given project
Summary
In this chapter, we started with big data problems and with an overview of big data and Apache Hadoop. We went through the history of Apache Hadoop's evolution, learned about what Hadoop offers today, and learned how it works. We also explored the architecture of Apache Hadoop, and new features and releases. Finally, we covered commercial implementations of Hadoop.
In the next chapter, we will learn about setting up an Apache Hadoop cluster in different modes.
