


















When kernel services are invoked in the current process context, its layout throws open the right path for exploring kernels in more detail. Our effort in this chapter is centered around comprehending processes and the underlying ecosystem the kernel provides for them. We will explore the following concepts in this chapter:
- Program to process
- Process layout
- Virtual address spaces
- Kernel and user space
- Process APIs
- Process descriptors
- Kernel stack management
- Threads
- Linux thread API
- Data structures
- Namespace and cgroups
Quintessentially, computing systems are designed, developed, and often tweaked for running user applications efficiently. Every element that goes into a computing platform is intended to enable effective and efficient ways for running applications. In other words, computing systems exist to run diverse application programs. Applications can run either as firmware in dedicated devices or as a "process" in systems driven by system software (operating systems).
At its core, a process is a running instance of a program in memory. The transformation from a program to a process happens when the program (on disk) is fetched into memory for execution.
A program’s binary image carries code (with all its binary instructions) and data (with all global data), which are mapped to distinct regions of memory with appropriate access permissions (read, write, and execute). Apart from code and data, a process is assigned additional memory regions called stack (for allocation of function call frames with auto variables and function arguments) and heap for dynamic allocations at runtime.
Multiple instances of the same program can exist with their respective memory allocations. For instance, for a web browser with multiple open tabs (running simultaneous browsing sessions), each tab is considered a process instance by the kernel, with unique memory allocations.
The following figure represents the layout of processes in memory:

Modern-day computing platforms are expected to handle a plethora of processes efficiently. Operating systems thus must deal with allocating unique memory to all contending processes within the physical memory (often finite) and also ensure their reliable execution. With multiple processes contending and executing simultaneously (multi-tasking), the operating system must ensure that the memory allocation of every process is protected from accidental access by another process.
To address this issue, the kernel provides a level of abstraction between the process and the physical memory called virtualaddress space. Virtual address space is the process' view of memory; it is how the running program views the memory.
Virtual address space creates an illusion that every process exclusively owns the whole memory while executing. This abstracted view of memory is called virtual memory and is achieved by the kernel's memory manager in coordination with the CPU's MMU. Each process is given a contiguous 32 or 64-bit address space, bound by the architecture and unique to that process. With each process caged into its virtual address space by the MMU, any attempt by a process to access an address region outside its boundaries will trigger a hardware fault, making it possible for the memory manger to detect and terminate violating processes, thus ensuring protection.
The following figure depicts the illusion of address space created for every contending process:

Modern operating systems not only prevent one process from accessing another but also prevent processes from accidentally accessing or manipulating kernel data and services (as the kernel is shared by all the processes).
Operating systems achieve this protection by segmenting the whole memory into two logical halves, the user and kernel space. This bifurcation ensures that all processes that are assigned address spaces are mapped to the user space section of memory and kernel data and services run in kernel space. The kernel achieves this protection in coordination with the hardware. While an application process is executing instructions from its code segment, the CPU is operating in user mode. When a process intends to invoke a kernel service, it needs to switch the CPU into privileged mode (kernel mode), which is achieved through special functions called APIs (application programming interfaces). These APIs enable user processes to switch into the kernel space using special CPU instructions and then execute the required services through system calls. On completion of the requested service, the kernel executes another mode switch, this time back from kernel mode to user mode, using another set of CPU instructions.
Note
System calls are the kernel's interfaces to expose its services to application processes; they are also called kernel entry points. As system calls are implemented in kernel space, the respective handlers are provided through APIs in the user space. API abstraction also makes it easier and convenient to invoke related system calls.
The following figure depicts a virtualized memory view:

When a process requests a kernel service through a system call, the kernel will execute on behalf of the caller process. The kernel is now said to be executing in process context. Similarly, the kernel also responds to interrupts raised by other hardware entities; here, the kernel executes in interrupt context. When in interrupt context, the kernel is not running on behalf of any process.
Right from the time a process is born until it exits, it’s the kernel's process management subsystem that carries out various operations, ranging from process creation, allocating CPU time, and event notifications to destruction of the process upon termination.
Apart from the address space, a process in memory is also assigned a data structure called the process descriptor, which the kernel uses to identify, manage, and schedule the process. The following figure depicts process address spaces with their respective process descriptors in the kernel:
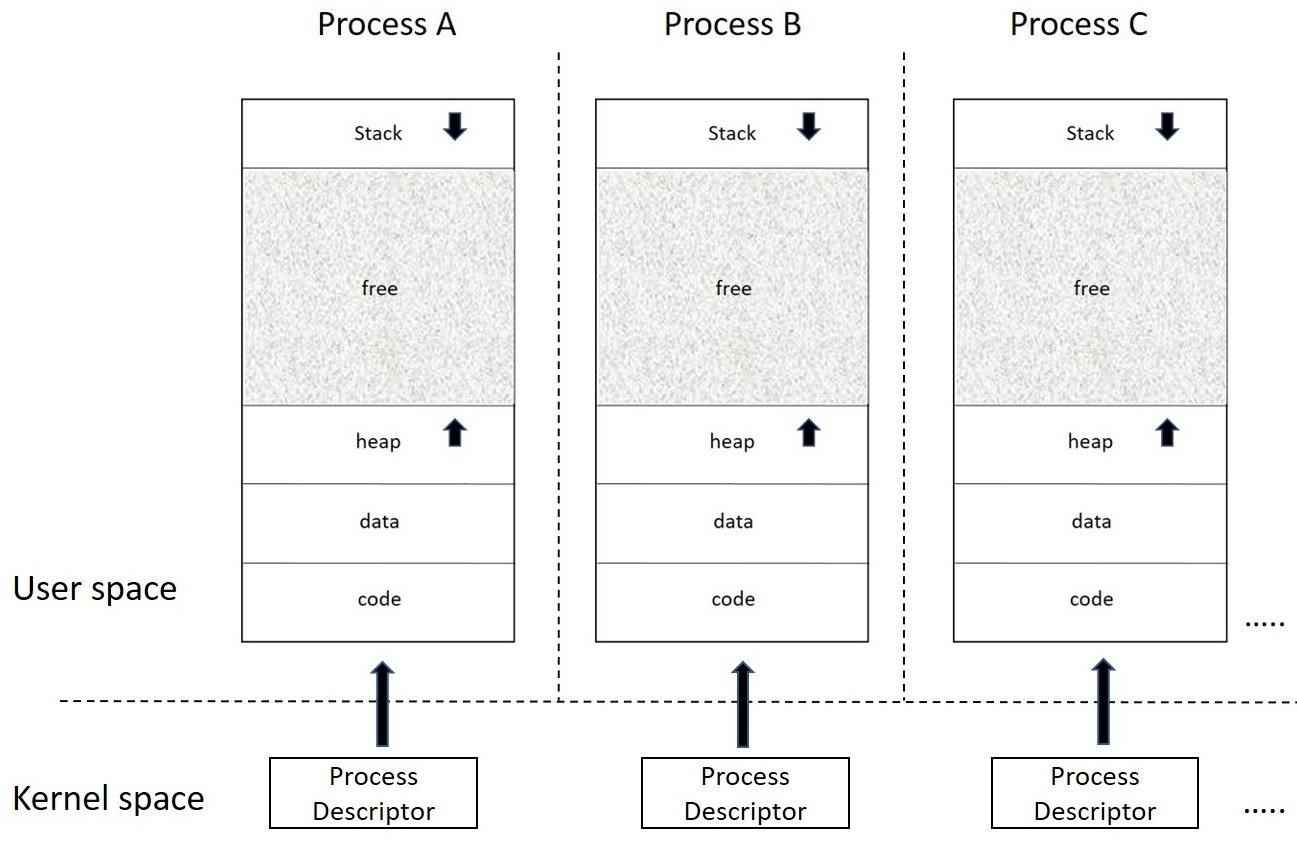
In Linux, a process descriptor is an instance of type struct task_struct defined in <linux/sched.h>, it is one of the central data structures, and contains all the attributes, identification details, and resource allocation entries that a process holds. Looking at struct task_struct is like a peek into the window of what the kernel sees or works with to manage and schedule a process.
Since the task structure contains a wide set of data elements, which are related to the functionality of various kernel subsystems, it would be out of context to discuss the purpose and scope of all the elements in this chapter. We shall consider a few important elements that are related to process management.
Process attributes define all the key and fundamental characteristics of a process. These elements contain the process's state and identifications along with other key values of importance.
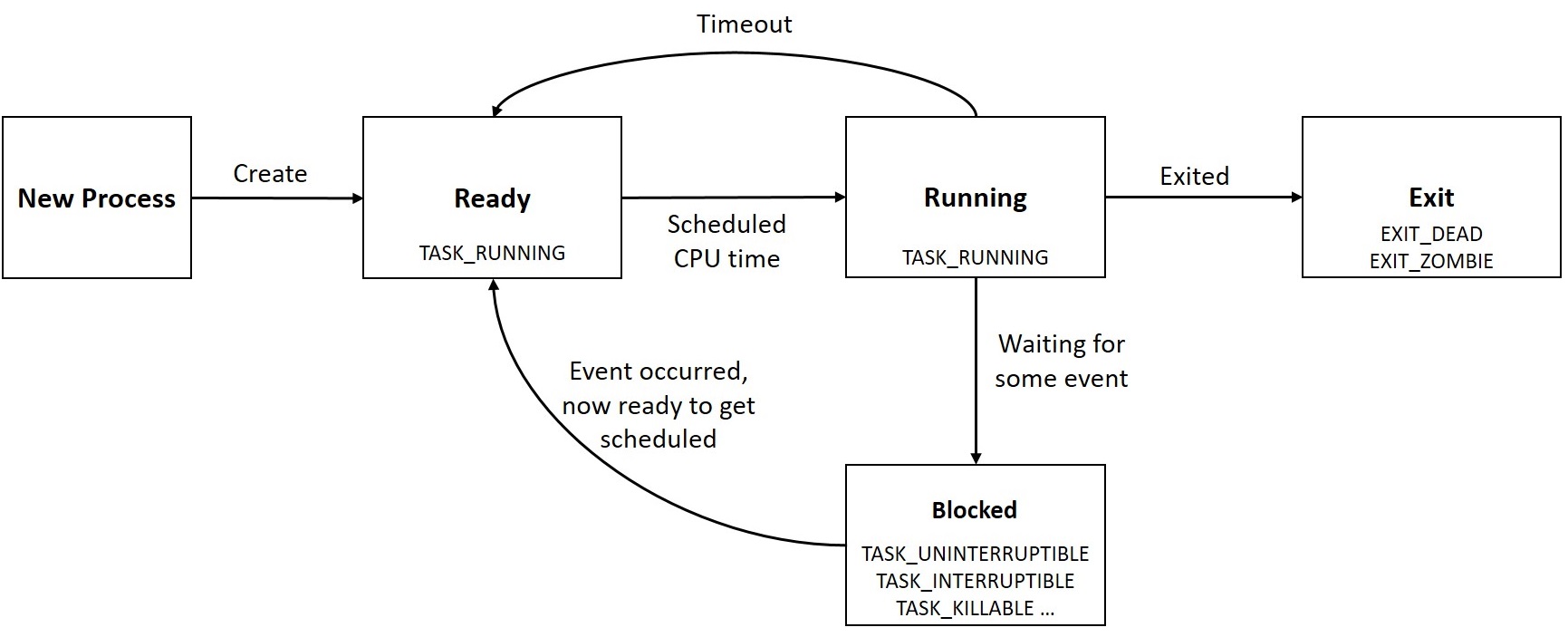
A process right from the time it is spawned until it exits may exist in various states, referred to as process states--they define the process’s current state:
- TASK_RUNNING (0): The task is either executing or contending for CPU in the scheduler run-queue.
- TASK_INTERRUPTIBLE (1): The task is in an interruptible wait state; it remains in wait until an awaited condition becomes true, such as the availability of mutual exclusion locks, device ready for I/O, lapse of sleep time, or an exclusive wake-up call. While in this wait state, any signals generated for the process are delivered, causing it to wake up before the wait condition is met.
- TASK_KILLABLE: This is similar to TASK_INTERRUPTIBLE, with the exception that interruptions can only occur on fatal signals, which makes it a better alternative to TASK_INTERRUPTIBLE.
- TASK_UNINTERRUTPIBLE (2): The task is in uninterruptible wait state similar to TASK_INTERRUPTIBLE, except that generated signals to the sleeping process do not cause wake-up. When the event occurs for which it is waiting, the process transitions to TASK_RUNNING. This process state is rarely used.
- TASK_ STOPPED (4): The task has received a STOP signal. It will be back to running on receiving the continue signal (SIGCONT).
- TASK_TRACED (8): A process is said to be in traced state when it is being combed, probably by a debugger.
- EXIT_ZOMBIE (32): The process is terminated, but its resources are not yet reclaimed.
- EXIT_DEAD (16): The child is terminated and all the resources held by it freed, after the parent collects the exit status of the child using wait.
The following figure depicts process states:
This field contains a unique process identifier referred to as PID. PIDs in Linux are of the type pid_t (integer). Though a PID is an integer, the default maximum number PIDs is 32,768 specified through the /proc/sys/kernel/pid_max interface. The value in this file can be set to any value up to 222 (PID_MAX_LIMIT, approximately 4 million).
To manage PIDs, the kernel uses a bitmap. This bitmap allows the kernel to keep track of PIDs in use and assign a unique PID for new processes. Each PID is identified by a bit in the PID bitmap; the value of a PID is determined from the position of its corresponding bit. Bits with value 1 in the bitmap indicate that the corresponding PIDs are in use, and those with value 0 indicate free PIDs. Whenever the kernel needs to assign a unique PID, it looks for the first unset bit and sets it to 1, and conversely to free a PID, it toggles the corresponding bit from 1 to 0.
This field contains the thread group id. For easy understanding, let's say when a new process is created, its PID and TGID are the same, as the process happens to be the only thread. When the process spawns a new thread, the new child gets a unique PID but inherits the TGID from the parent, as it belongs to the same thread group. The TGID is primarily used to support multi-threaded process. We will delve into further details in the threads section of this chapter.
This field holds processor-specific state information, and is a critical element of the task structure. Later sections of this chapter contain details about the importance of thread_info.
The flags field records various attributes corresponding to a process. Each bit in the field corresponds to various stages in the lifetime of a process. Per-process flags are defined in <linux/sched.h>:
#define PF_EXITING /* getting shut down */ #define PF_EXITPIDONE /* pi exit done on shut down */ #define PF_VCPU /* I'm a virtual CPU */ #define PF_WQ_WORKER /* I'm a workqueue worker */ #define PF_FORKNOEXEC /* forked but didn't exec */ #define PF_MCE_PROCESS /* process policy on mce errors */ #define PF_SUPERPRIV /* used super-user privileges */ #define PF_DUMPCORE /* dumped core */ #define PF_SIGNALED /* killed by a signal */ #define PF_MEMALLOC /* Allocating memory */ #define PF_NPROC_EXCEEDED /* set_user noticed that RLIMIT_NPROC was exceeded */ #define PF_USED_MATH /* if unset the fpu must be initialized before use */ #define PF_USED_ASYNC /* used async_schedule*(), used by module init */ #define PF_NOFREEZE /* this thread should not be frozen */ #define PF_FROZEN /* frozen for system suspend */ #define PF_FSTRANS /* inside a filesystem transaction */ #define PF_KSWAPD /* I am kswapd */ #define PF_MEMALLOC_NOIO0 /* Allocating memory without IO involved */ #define PF_LESS_THROTTLE /* Throttle me less: I clean memory */ #define PF_KTHREAD /* I am a kernel thread */ #define PF_RANDOMIZE /* randomize virtual address space */ #define PF_SWAPWRITE /* Allowed to write to swap */ #define PF_NO_SETAFFINITY /* Userland is not allowed to meddle with cpus_allowed */ #define PF_MCE_EARLY /* Early kill for mce process policy */ #define PF_MUTEX_TESTER /* Thread belongs to the rt mutex tester */ #define PF_FREEZER_SKIP /* Freezer should not count it as freezable */ #define PF_SUSPEND_TASK /* this thread called freeze_processes and should not be frozen */
Every process can be related to a parent process, establishing a parent-child relationship. Similarly, multiple processes spawned by the same process are called siblings. These fields establish how the current process relates to another process.
These are pointers to the parent's task structure. For a normal process, both these pointers refer to the same task_struct; they only differ for multi-thread processes, implemented using posix threads. For such cases, real_parent refers to the parent thread task structure and parent refers the process task structure to which SIGCHLD is delivered.
All contending processes must be given fair CPU time, and this calls for scheduling based on time slices and process priorities. These attributes contain necessary information that the scheduler uses when deciding on which process gets priority when contending.
prio helps determine the priority of the process for scheduling. This field holds static priority of the process within the range 1 to 99 (as specified by sched_setscheduler()) if the process is assigned a real-time scheduling policy. For normal processes, this field holds a dynamic priority derived from the nice value.
Every task belongs to a scheduling entity (group of tasks), as scheduling is done at a per-entity level. se is for all normal processes, rt is for real-time processes, and dl is for deadline processes. We will discuss more on these attributes in the next chapter on scheduling.
This field contains information about the scheduling policy of the process, which helps in determining its priority.
The kernel imposes resource limits to ensure fair allocation of system resources among contending processes. These limits guarantee that a random process does not monopolize ownership of resources. There are 16 different types of resource limits, and the task structure points to an array of type struct rlimit, in which each offset holds the current and maximum values for a specific resource.
/*include/uapi/linux/resource.h*/
struct rlimit {
__kernel_ulong_t rlim_cur;
__kernel_ulong_t rlim_max;
};
These limits are specified in include/uapi/asm-generic/resource.h
#define RLIMIT_CPU 0 /* CPU time in sec */
#define RLIMIT_FSIZE 1 /* Maximum filesize */
#define RLIMIT_DATA 2 /* max data size */
#define RLIMIT_STACK 3 /* max stack size */
#define RLIMIT_CORE 4 /* max core file size */
#ifndef RLIMIT_RSS
# define RLIMIT_RSS 5 /* max resident set size */
#endif
#ifndef RLIMIT_NPROC
# define RLIMIT_NPROC 6 /* max number of processes */
#endif
#ifndef RLIMIT_NOFILE
# define RLIMIT_NOFILE 7 /* max number of open files */
#endif
#ifndef RLIMIT_MEMLOCK
# define RLIMIT_MEMLOCK 8 /* max locked-in-memory
address space */
#endif
#ifndef RLIMIT_AS
# define RLIMIT_AS 9 /* address space limit */
#endif
#define RLIMIT_LOCKS 10 /* maximum file locks held */
#define RLIMIT_SIGPENDING 11 /* max number of pending signals */
#define RLIMIT_MSGQUEUE 12 /* maximum bytes in POSIX mqueues */
#define RLIMIT_NICE 13 /* max nice prio allowed to
raise to 0-39 for nice level 19 .. -20 */
#define RLIMIT_RTPRIO 14 /* maximum realtime priority */
#define RLIMIT_RTTIME 15 /* timeout for RT tasks in us */
#define RLIM_NLIMITS 16During the lifetime of a process, it may access various resource files to get its task done. This results in the process opening, closing, reading, and writing to these files. The system must keep track of these activities; file descriptor elements help the system know which files the process holds.
For processes to handle signals, the task structure has various elements that determine how the signals must be handled.
This is of type struct signal_struct, which contains information on all the signals associated with the process.
This is of type struct sighand_struct, which contains all signal handlers associated with the process.
With current-generation computing platforms powered by multi-core hardware capable of running simultaneous applications, the possibility of multiple processes concurrently initiating kernel mode switch when requesting for the same process is built in. To be able to handle such situations, kernel services are designed to be re-entrant, allowing multiple processes to step in and engage the required services. This mandated the requesting process to maintain its own private kernel stack to keep track of the kernel function call sequence, store local data of the kernel functions, and so on.
The kernel stack is directly mapped to the physical memory, mandating the arrangement to be physically in a contiguous region. The kernel stack by default is 8kb for x86-32 and most other 32-bit systems (with an option of 4k kernel stack to be configured during kernel build), and 16kb on an x86-64 system.
When kernel services are invoked in the current process context, they need to validate the process’s prerogative before it commits to any relevant operations. To perform such validations, the kernel services must gain access to the task structure of the current process and look through the relevant fields. Similarly, kernel routines might need to have access to the current task structure for modifying various resource structures such as signal handler tables, looking for pending signals, file descriptor table, and memory descriptor among others. To enable accessing the task structure at runtime, the address of the current task structure is loaded into a processor register (register chosen is architecture specific) and made available through a kernel global macro called current (defined in architecture-specific kernel header asm/current.h ):
/* arch/ia64/include/asm/current.h */
#ifndef _ASM_IA64_CURRENT_H
#define _ASM_IA64_CURRENT_H
/*
* Modified 1998-2000
* David Mosberger-Tang <davidm@hpl.hp.com>, Hewlett-Packard Co
*/
#include <asm/intrinsics.h>
/*
* In kernel mode, thread pointer (r13) is used to point to the
current task
* structure.
*/
#define current ((struct task_struct *) ia64_getreg(_IA64_REG_TP))
#endif /* _ASM_IA64_CURRENT_H */
/* arch/powerpc/include/asm/current.h */
#ifndef _ASM_POWERPC_CURRENT_H
#define _ASM_POWERPC_CURRENT_H
#ifdef __KERNEL__
/*
* This program is free software; you can redistribute it and/or
* modify it under the terms of the GNU General Public License
* as published by the Free Software Foundation; either version
* 2 of the License, or (at your option) any later version.
*/
struct task_struct;
#ifdef __powerpc64__
#include <linux/stddef.h>
#include <asm/paca.h>
static inline struct task_struct *get_current(void)
{
struct task_struct *task;
__asm__ __volatile__("ld %0,%1(13)"
: "=r" (task)
: "i" (offsetof(struct paca_struct, __current)));
return task;
}
#define current get_current()
#else
/*
* We keep `current' in r2 for speed.
*/
register struct task_struct *current asm ("r2");
#endif
#endif /* __KERNEL__ */
#endif /* _ASM_POWERPC_CURRENT_H */However, in register-constricted architectures, where there are few registers to spare, reserving a register to hold the address of the current task structure is not viable. On such platforms, the task structure of the current process is directly made available at the top of the kernel stack that it owns. This approach renders a significant advantage with respect to locating the task structure, by just masking the least significant bits of the stack pointer.
With the evolution of the kernel, the task structure grew and became too large to be contained in the kernel stack, which is already restricted in physical memory (8Kb). As a result, the task structure was moved out of the kernel stack, barring a few key fields that define the process's CPU state and other low-level processor-specific information. These fields were then wrapped in a newly created structure called struct thread_info. This structure is contained on top of the kernel stack and provides a pointer that refers to the current task structure, which can be used by kernel services.
The following code snippet shows struct thread_info for x86 architecture (kernel 3.10):
/* linux-3.10/arch/x86/include/asm/thread_info.h */ struct thread_info { struct task_struct *task; /* main task structure */ struct exec_domain *exec_domain; /* execution domain */ __u32 flags; /* low level flags */ __u32 status; /* thread synchronous flags */ __u32 cpu; /* current CPU */ int preempt_count; /* 0 => preemptable, <0 => BUG */ mm_segment_t addr_limit; struct restart_block restart_block; void __user *sysenter_return; #ifdef CONFIG_X86_32 unsigned long previous_esp; /* ESP of the previous stack in case of nested (IRQ) stacks */ __u8 supervisor_stack[0]; #endif unsigned int sig_on_uaccess_error:1; unsigned int uaccess_err:1; /* uaccess failed */ };
With thread_info containing process-related information, apart from task structure, the kernel has multiple viewpoints to the current process structure: struct task_struct, an architecture-independent information block, and thread_info, an architecture-specific one. The following figure depicts thread_info and task_struct:

For architectures that engage thread_info, the current macro's implementation is modified to look into the top of kernel stack to obtain a reference to the current thread_info and through it the current task structure. The following code snippet shows the implementation of current for an x86-64 platform:
#ifndef __ASM_GENERIC_CURRENT_H #define __ASM_GENERIC_CURRENT_H #include <linux/thread_info.h> #define get_current() (current_thread_info()->task) #define current get_current() #endif /* __ASM_GENERIC_CURRENT_H */ /* * how to get the current stack pointer in C */ register unsigned long current_stack_pointer asm ("sp"); /* * how to get the thread information struct from C */ static inline struct thread_info *current_thread_info(void) __attribute_const__; static inline struct thread_info *current_thread_info(void) { return (struct thread_info *) (current_stack_pointer & ~(THREAD_SIZE - 1)); }
As use of PER_CPU variables has increased in recent times, the process scheduler is tuned to cache crucial current process-related information in the PER_CPU area. This change enables quick access to current process data over looking up the kernel stack. The following code snippet shows the implementation of the current macro to fetch the current task data through the PER_CPU variable:
#ifndef _ASM_X86_CURRENT_H #define _ASM_X86_CURRENT_H #include <linux/compiler.h> #include <asm/percpu.h> #ifndef __ASSEMBLY__ struct task_struct; DECLARE_PER_CPU(struct task_struct *, current_task); static __always_inline struct task_struct *get_current(void) { return this_cpu_read_stable(current_task); } #define current get_current() #endif /* __ASSEMBLY__ */ #endif /* _ASM_X86_CURRENT_H */
The use of PER_CPU data led to a gradual reduction of information in thread_info. With thread_info shrinking in size, kernel developers are considering getting rid of thread_info altogether by moving it into the task structure. As this involves changes to low-level architecture code, it has only been implemented for the x86-64 architecture, with other architectures planned to follow. The following code snippet shows the current state of the thread_info structure with just one element:
/* linux-4.9.10/arch/x86/include/asm/thread_info.h */
struct thread_info {
unsigned long flags; /* low level flags */
};Unlike user mode, the kernel mode stack lives in directly mapped memory. When a process invokes a kernel service, which may internally be deeply nested, chances are that it may overrun into immediate memory range. The worst part of it is the kernel will be oblivious to such occurrences. Kernel programmers usually engage various debug options to track stack usage and detect overruns, but these methods are not handy to prevent stack breaches on production systems.Conventional protection through the use of guard pages is also ruled out here (as it wastes an actual memory page).
Kernel programmers tend to follow coding standards--minimizing the use of local data, avoiding recursion, and avoiding deep nesting among others--to cut down the probability of a stack breach. However, implementation of feature-rich and deeply layered kernel subsystems may pose various design challenges and complications, especially with the storage subsystem where filesystems, storage drivers, and networking code can be stacked up in several layers, resulting in deeply nested function calls.
The Linux kernel community has been pondering over preventing such breaches for quite long, and toward that end, the decision was made to expand the kernel stack to 16kb (x86-64, since kernel 3.15). Expansion of the kernel stack might prevent some breaches, but at the cost of engaging much of the directly mapped kernel memory for the per-process kernel stack. However, for reliable functioning of the system, it is expected of the kernel to elegantly handle stack breaches when they show up on production systems.
With the 4.9 release, the kernel has come with a new system to set up virtually mapped kernel stacks. Since virtual addresses are currently in use to map even a directly mapped page, principally the kernel stack does not actually require physically contiguous pages. The kernel reserves a separate range of addresses for virtually mapped memory, and addresses from this range are allocated when a call to vmalloc() is made. This range of memory is referred as the vmalloc range. Primarily this range is used when programs require huge chunks of memory which are virtually contiguous but physically scattered. Using this, the kernel stack can now be allotted as individual pages, mapped to the vmalloc range. Virtual mapping also enables protection from overruns as a no-access guard page can be allocated with a page table entry (without wasting an actual page). Guard pages would prompt the kernel to pop an oops message on memory overrun and initiate a kill against overrunning process.
Virtually mapped kernel stacks with guard pages are currently available only for the x86-64 architecture (support for other architectures seemingly to follow). This can be enabled by choosing the HAVE_ARCH_VMAP_STACK or CONFIG_VMAP_STACK build-time options.
During kernel boot, a kernel thread called init is spawned, which in turn is configured to initialize the first user-mode process (with the same name). The init (pid 1) process is then configured to carry out various initialization operations specified through configuration files, creating multiple processes. Every child process further created (which may in turn create its own child process(es)) are all descendants of the init process. Processes thus created end up in a tree-like structure or a single hierarchy model. The shell, which is one such process, becomes the interface for users to create user processes, when programs are called for execution.
Fork, vfork, exec, clone, wait and exit are the core kernel interfaces for the creation and control of new process. These operations are invoked through corresponding user-mode APIs.
Fork() is one of the core "Unix thread APIs" available across *nix systems since the inception of legacy Unix releases. Aptly named, it forks a new process from a running process. When fork() succeeds, the new process is created (referred to as child) by duplicating the caller's address space and task structure. On return from fork(), both caller (parent) and new process (child) resume executing instructions from the same code segment which was duplicated under copy-on-write. Fork() is perhaps the only API that enters kernel mode in the context of caller process, and on success returns to user mode in the context of both caller and child (new process).
Most resource entries of the parent's task structure such as memory descriptor, file descriptor table, signal descriptors, and scheduling attributes are inherited by the child, except for a few attributes such as memory locks, pending signals, active timers, and file record locks (for the full list of exceptions, refer to the fork(2) man page). A child process is assigned a unique pid and will refer to its parent's pid through the ppid field of its task structure; the child’s resource utilization and processor usage entries are reset to zero.
The parent process updates itself about the child’s state using the wait() system call and normally waits for the termination of the child process. Failing to call wait(), the child may terminate and be pushed into a zombie state.
Duplication of parent process to create a child needs cloning of the user mode address space (stack, data, code, and heap segments) and task structure of the parent for the child; this would result in execution overhead that leads to un-deterministic process-creation time. To make matters worse, this process of cloning would be rendered useless if neither parent nor child did not initiate any state-change operations on cloned resources.
As per COW, when a child is created, it is allocated a unique task structure with all resource entries (including page tables) referring to the parent's task structure, with read-only access for both parent and child. Resources are truly duplicated when either of the processes initiates a state change operation, hence the name copy-on-write (write in COW implies a state change). COW does bring effectiveness and optimization to the fore, by deferring the need for duplicating process data until write, and in cases where only read happens, it avoids it altogether. This on-demand copying also reduces the number of swap pages needed, cuts down the time spent on swapping, and might help reduce demand paging.
At times creating a child process might not be useful, unless it runs a new program altogether: the exec family of calls serves precisely this purpose. exec replaces the existing program in a process with a new executable binary:
#include <unistd.h> int execve(const char *filename, char *const argv[], char *const envp[]);
The execve is the system call that executes the program binary file, passed as the first argument to it. The second and third arguments are null-terminated arrays of arguments and environment strings, to be passed to a new program as command-line arguments. This system call can also be invoked through various glibc (library) wrappers, which are found to be more convenient and flexible:
#include <unistd.h> extern char **environ; int execl(const char *path, const char *arg, ...); int execlp(const char *file, const char *arg, ...); int execle(const char *path, const char *arg, ..., char * const envp[]); int execv(const char *path, char *constargv[]); int execvp(const char *file, char *constargv[]); int execvpe(const char *file, char *const argv[], char *const envp[]);
Command-line user-interface programs such as shell use the exec interface to launch user-requested program binaries.
Unlike fork(), vfork() creates a child process and blocks the parent, which means that the child runs as a single thread and does not allow concurrency; in other words, the parent process is temporarily suspended until the child exits or call exec(). The child shares the data of the parent.
The flow of execution in a process is referred to as a thread, which implies that every process will at least have one thread of execution. Multi-threaded means the existence of multiple flows of execution contexts in a process. With modern many-core architectures, multiple flows of execution in a process can be truly concurrent, achieving fair multitasking.
Threads are normally enumerated as pure user-level entities within a process that are scheduled for execution; they share parent's virtual address space and system resources. Each thread maintains its code, stack, and thread local storage. Threads are scheduled and managed by the thread library, which uses a structure referred to as a thread object to hold a unique thread identifier, for scheduling attributes and to save the thread context. User-level thread applications are generally lighter on memory, and are the preferred model of concurrency for event-driven applications. On the flip side, such user-level thread model is not suitable for parallel computing, since they are tied onto the same processor core to which their parent process is bound.
Linux doesn’t support user-level threads directly; it instead proposes an alternate API to enumerate a special process, called light weight process (LWP), that can share a set of configured resources such as dynamic memory allocations, global data, open files, signal handlers, and other extensive resources with the parent process. Each LWP is identified by a unique PID and task structure, and is treated by the kernel as an independent execution context. In Linux, the term thread invariably refers to LWP, since each thread initialized by the thread library (Pthreads) is enumerated as an LWP by the kernel.
clone() is a Linux-specific system call to create a new process; it is considered a generic version of the fork() system call, offering finer controls to customize its functionality through the flags argument:
int clone(int (*child_func)(void *), void *child_stack, int flags, void *arg);
It provides more than twenty different CLONE_* flags that control various aspects of the clone operation, including whether the parent and child process share resources such as virtual memory, open file descriptors, and signal dispositions. The child is created with the appropriate memory address (passed as the second argument) to be used as the stack (for storing the child's local data). The child process starts its execution with its start function (passed as the first argument to the clone call).
When a process attempts to create a thread through the pthread library, clone() is invoked with the following flags:
/*clone flags for creating threads*/ flags=CLONE_VM|CLONE_FS|CLONE_FILES|CLONE_SIGHAND|CLONE_THREAD|CLONE_SYSVSEM|CLONE_SETTLS|CLONE_PARENT_SETTID|CLONE_CHILD_CLEARTID;

The clone() can also be used to create a regular child process that is normally spawned using fork() and vfork():
/* clone flags for forking child */ flags = SIGCHLD; /* clone flags for vfork child */ flags = CLONE_VFORK | CLONE_VM | SIGCHLD;
To augment the need for running background operations, the kernel spawns threads (similar to processes). These kernel threads are similar to regular processes, in that they are represented by a task structure and assigned a PID. Unlike user processes, they do not have any address space mapped, and run exclusively in kernel mode, which makes them non-interactive. Various kernel subsystems use kthreads to run periodic and asynchronous operations.
All kernel threads are descendants of kthreadd (pid 2), which is spawned by the kernel (pid 0) during boot. The kthreadd enumerates other kernel threads; it provides interface routines through which other kernel threads can be dynamically spawned at runtime by kernel services. Kernel threads can be viewed from the command line with the ps -ef command--they are shown in [square brackets]:
UID PID PPID C STIME TTY TIME CMD
root 1 0 0 22:43 ? 00:00:01 /sbin/init splash
root 2 0 0 22:43 ? 00:00:00 [kthreadd]
root 3 2 0 22:43 ? 00:00:00 [ksoftirqd/0]
root 4 2 0 22:43 ? 00:00:00 [kworker/0:0]
root 5 2 0 22:43 ? 00:00:00 [kworker/0:0H]
root 7 2 0 22:43 ? 00:00:01 [rcu_sched]
root 8 2 0 22:43 ? 00:00:00 [rcu_bh]
root 9 2 0 22:43 ? 00:00:00 [migration/0]
root 10 2 0 22:43 ? 00:00:00 [watchdog/0]
root 11 2 0 22:43 ? 00:00:00 [watchdog/1]
root 12 2 0 22:43 ? 00:00:00 [migration/1]
root 13 2 0 22:43 ? 00:00:00 [ksoftirqd/1]
root 15 2 0 22:43 ? 00:00:00 [kworker/1:0H]
root 16 2 0 22:43 ? 00:00:00 [watchdog/2]
root 17 2 0 22:43 ? 00:00:00 [migration/2]
root 18 2 0 22:43 ? 00:00:00 [ksoftirqd/2]
root 20 2 0 22:43 ? 00:00:00 [kworker/2:0H]
root 21 2 0 22:43 ? 00:00:00 [watchdog/3]
root 22 2 0 22:43 ? 00:00:00 [migration/3]
root 23 2 0 22:43 ? 00:00:00 [ksoftirqd/3]
root 25 2 0 22:43 ? 00:00:00 [kworker/3:0H]
root 26 2 0 22:43 ? 00:00:00 [kdevtmpfs]
/*kthreadd creation code (init/main.c) */
static noinline void __ref rest_init(void)
{
int pid;
rcu_scheduler_starting();
/*
* We need to spawn init first so that it obtains pid 1, however
* the init task will end up wanting to create kthreads, which, if
* we schedule it before we create kthreadd, will OOPS.
*/
kernel_thread(kernel_init, NULL, CLONE_FS);
numa_default_policy();
pid = kernel_thread(kthreadd, NULL, CLONE_FS | CLONE_FILES);
rcu_read_lock();
kthreadd_task = find_task_by_pid_ns(pid, &init_pid_ns);
rcu_read_unlock();
complete(&kthreadd_done);
/*
* The boot idle thread must execute schedule()
* at least once to get things moving:
*/
init_idle_bootup_task(current);
schedule_preempt_disabled();
/* Call into cpu_idle with preempt disabled */
cpu_startup_entry(CPUHP_ONLINE);
}The previous code shows the kernel boot routine rest_init() invoking the kernel_thread() routine with appropriate arguments to spawn both the kernel_init thread (which then goes on to start the user-mode init process) and kthreadd.
The kthread is a perpetually running thread that looks into a list called kthread_create_list for data on new kthreads to be created:
/*kthreadd routine(kthread.c) */
int kthreadd(void *unused)
{
struct task_struct *tsk = current;
/* Setup a clean context for our children to inherit. */
set_task_comm(tsk, "kthreadd");
ignore_signals(tsk);
set_cpus_allowed_ptr(tsk, cpu_all_mask);
set_mems_allowed(node_states[N_MEMORY]);
current->flags |= PF_NOFREEZE;
for (;;) {
set_current_state(TASK_INTERRUPTIBLE);
if (list_empty(&kthread_create_list))
schedule();
__set_current_state(TASK_RUNNING);
spin_lock(&kthread_create_lock);
while (!list_empty(&kthread_create_list)) {
struct kthread_create_info *create;
create = list_entry(kthread_create_list.next,
struct kthread_create_info, list);
list_del_init(&create->list);
spin_unlock(&kthread_create_lock);
create_kthread(create); /* creates kernel threads with attributes enqueued */
spin_lock(&kthread_create_lock);
}
spin_unlock(&kthread_create_lock);
}
return 0;
}Kernel threads are created by invoking either kthread_create or through its wrapper kthread_run by passing appropriate arguments that define the kthreadd (start routine, ARG data to start routine, and name). The following code snippet shows kthread_create invoking kthread_create_on_node(), which by default creates threads on the current Numa node:
struct task_struct *kthread_create_on_node(int (*threadfn)(void *data), void *data, int node, const char namefmt[], ...); /** * kthread_create - create a kthread on the current node * @threadfn: the function to run in the thread * @data: data pointer for @threadfn() * @namefmt: printf-style format string for the thread name * @...: arguments for @namefmt. * * This macro will create a kthread on the current node, leaving it in * the stopped state. This is just a helper for * kthread_create_on_node(); * see the documentation there for more details. */ #define kthread_create(threadfn, data, namefmt, arg...) kthread_create_on_node(threadfn, data, NUMA_NO_NODE, namefmt, ##arg) struct task_struct *kthread_create_on_cpu(int (*threadfn)(void *data), void *data, unsigned int cpu, const char *namefmt); /** * kthread_run - create and wake a thread. * @threadfn: the function to run until signal_pending(current). * @data: data ptr for @threadfn. * @namefmt: printf-style name for the thread. * * Description: Convenient wrapper for kthread_create() followed by * wake_up_process(). Returns the kthread or ERR_PTR(-ENOMEM). */ #define kthread_run(threadfn, data, namefmt, ...) ({ struct task_struct *__k = kthread_create(threadfn, data, namefmt, ## __VA_ARGS__); if (!IS_ERR(__k)) wake_up_process(__k); __k; })
kthread_create_on_node() instantiates details (received as arguments) of kthread to be created into a structure of type kthread_create_info and queues it at the tail of kthread_create_list. It then wakes up kthreadd and waits for thread creation to complete:
/* kernel/kthread.c */
static struct task_struct *__kthread_create_on_node(int (*threadfn)(void *data),
void *data, int node,
const char namefmt[],
va_list args)
{
DECLARE_COMPLETION_ONSTACK(done);
struct task_struct *task;
struct kthread_create_info *create = kmalloc(sizeof(*create),
GFP_KERNEL);
if (!create)
return ERR_PTR(-ENOMEM);
create->threadfn = threadfn;
create->data = data;
create->node = node;
create->done = &done;
spin_lock(&kthread_create_lock);
list_add_tail(&create->list, &kthread_create_list);
spin_unlock(&kthread_create_lock);
wake_up_process(kthreadd_task);
/*
* Wait for completion in killable state, for I might be chosen by
* the OOM killer while kthreadd is trying to allocate memory for
* new kernel thread.
*/
if (unlikely(wait_for_completion_killable(&done))) {
/*
* If I was SIGKILLed before kthreadd (or new kernel thread)
* calls complete(), leave the cleanup of this structure to
* that thread.
*/
if (xchg(&create->done, NULL))
return ERR_PTR(-EINTR);
/*
* kthreadd (or new kernel thread) will call complete()
* shortly.
*/
wait_for_completion(&done); // wakeup on completion of thread creation.
}
...
...
...
}
struct task_struct *kthread_create_on_node(int (*threadfn)(void *data),
void *data, int node,
const char namefmt[],
...)
{
struct task_struct *task;
va_list args;
va_start(args, namefmt);
task = __kthread_create_on_node(threadfn, data, node, namefmt, args);
va_end(args);
return task;
}Recall that kthreadd invokes the create_thread() routine to start kernel threads as per data queued into the list. This routine creates the thread and signals completion:
/* kernel/kthread.c */
static void create_kthread(struct kthread_create_info *create)
{
int pid;
#ifdef CONFIG_NUMA
current->pref_node_fork = create->node;
#endif
/* We want our own signal handler (we take no signals by default). */
pid = kernel_thread(kthread, create, CLONE_FS | CLONE_FILES |
SIGCHLD);
if (pid < 0) {
/* If user was SIGKILLed, I release the structure. */
struct completion *done = xchg(&create->done, NULL);
if (!done) {
kfree(create);
return;
}
create->result = ERR_PTR(pid);
complete(done); /* signal completion of thread creation */
}
}All of the process/thread creation calls discussed so far invoke different system calls (except create_thread) to step into kernel mode. All of those system calls in turn converge into the common kernel function _do_fork(), which is invoked with distinct CLONE_* flags. do_fork() internally falls back on copy_process() to complete the task. The following figure sums up the call sequence for process creation:
/* kernel/fork.c */ /* * Create a kernel thread. */
pid_t kernel_thread(int (*fn)(void *), void *arg, unsigned long flags) { return _do_fork(flags|CLONE_VM|CLONE_UNTRACED, (unsigned long)fn, (unsigned long)arg, NULL, NULL, 0); } /* sys_fork: create a child process by duplicating caller */ SYSCALL_DEFINE0(fork) { #ifdef CONFIG_MMU return _do_fork(SIGCHLD, 0, 0, NULL, NULL, 0); #else /* cannot support in nommu mode */ return -EINVAL; #endif } /* sys_vfork: create vfork child process */ SYSCALL_DEFINE0(vfork) { return _do_fork(CLONE_VFORK | CLONE_VM | SIGCHLD, 0, 0, NULL, NULL, 0); } /* sys_clone: create child process as per clone flags */ #ifdef __ARCH_WANT_SYS_CLONE #ifdef CONFIG_CLONE_BACKWARDS SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp, int __user *, parent_tidptr, unsigned long, tls, int __user *, child_tidptr) #elif defined(CONFIG_CLONE_BACKWARDS2) SYSCALL_DEFINE5(clone, unsigned long, newsp, unsigned long, clone_flags, int __user *, parent_tidptr, int __user *, child_tidptr, unsigned long, tls) #elif defined(CONFIG_CLONE_BACKWARDS3) SYSCALL_DEFINE6(clone, unsigned long, clone_flags, unsigned long, newsp, int, stack_size, int __user *, parent_tidptr, int __user *, child_tidptr, unsigned long, tls) #else SYSCALL_DEFINE5(clone, unsigned long, clone_flags, unsigned long, newsp, int __user *, parent_tidptr, int __user *, child_tidptr, unsigned long, tls) #endif { return _do_fork(clone_flags, newsp, 0, parent_tidptr, child_tidptr, tls); } #endif

During the lifetime of a process, it traverses through many states before it ultimately terminates. Users must have proper mechanisms to be updated with all that happens to a process during its lifetime. Linux provides a set of functions for this purpose.
For processes and threads created by a parent, it might be functionally useful for the parent to know the execution status of the child process/thread. This can be achieved using the wait family of system calls:
#include <sys/types.h> #include <sys/wait.h> pid_t wait(int *status); pid_t waitpid(pid_t pid, int *status, intoptions); int waitid(idtype_t idtype, id_t id, siginfo_t *infop, int options)
These system calls update the calling process with the state change events of a child. The following state change events are notified:
- Termination of child
- Stopped by a signal
- Resumed by a signal
In addition to reporting the status, these APIs allow the parent process to reap a terminated child. A process on termination is put into zombie state until the immediate parent engages the wait call to reap it.
Every process must end. Process termination is done either by the process calling exit() or when the main function returns. A process may also be terminated abruptly on receiving a signal or exception that forces it to terminate, such as the KILL command, which sends a signal to kill the process, or when an exception is raised. Upon termination, the process is put into exit state until the immediate parent reaps it.
The exit calls the sys_exit system call, which internally calls the do_exit routine. The do_exit primarily performs the following tasks (do_exit sets many values and makes multiple calls to related kernel routines to complete its task):
- Takes the exit code returned by the child to the parent.
- Sets the
PF_EXITINGflag, indicating process exiting. - Cleans up and reclaims the resources held by the process. This includes releasing
mm_struct, removal from the queue if it is waiting for an IPC semaphore, release of filesystem data and files, if any, and callingschedule()as the process is no longer executable.
After do_exit, the process remains in zombie state and the process descriptor is still intact for the parent to collect the status, after which the resources are reclaimed by the system.
Users logged into a Linux system have a transparent view of various system entities such as global resources, processes, kernel, and users. For instance, a valid user can access PIDs of all running processes on the system (irrespective of the user to which they belong). Users can observe the presence of other users on the system, and they can run commands to view the state of global system global resources such as memory, filesystem mounts, and devices. Such operations are not deemed as intrusions or considered security breaches, as it is always guaranteed that one user/process can never intrude into other user/process.
However, such transparency is unwarranted on a few server platforms. For instance, consider cloud service providers offering PaaS (platform as a service). They offer an environment to host and deploy custom client applications. They manage runtime, storage, operating system, middleware, and networking services, leaving customers to manage their applications and data. PaaS services are used by various e-commerce, financial, online gaming, and other related enterprises.
For efficient and effective isolation and resource management for clients, PaaS service providers use various tools. They virtualize the system environment for each client to achieve security, reliability, and robustness. The Linux kernel provides low-level mechanisms in the form of cgroups and namespaces for building various lightweight tools that can virtualize the system environment. Docker is one such framework that builds on cgroups and namespaces.
Namespaces fundamentally are mechanisms to abstract, isolate, and limit the visibility that a group of processes has over various system entities such as process trees, network interfaces, user IDs, and filesystem mounts. Namespaces are categorized into several groups, which we will now see.
Traditionally, mount and unmount operations will change the filesystem view as seen by all processes in the system; in other words, there is one global mount namespace seen by all processes. The mount namespaces confine the set of filesystem mount points visible within a process namespace, enabling one process group in a mount namespace to have an exclusive view of the filesystem list compared to another process.
These enable isolating the system's host and domain name within a uts namespace. This makes initialization and configuration scripts able to be guided based on the respective namespaces.
These demarcate processes from using System V and POSIX message queues. This prevents one process from an ipc namespace accessing the resources of another.
Traditionally, *nix kernels (including Linux) spawn the init process with PID 1 during system boot, which in turn starts other user-mode processes and is considered the root of the process tree (all the other processes start below this process in the tree). The PID namespace allows a process to spin off a new tree of processes under it with its own root process (PID 1 process). PID namespaces isolate process ID numbers, and allow duplication of PID numbers across different PID namespaces, which means that processes in different PID namespaces can have the same process ID. The process IDs within a PID namespace are unique, and are assigned sequentially starting with PID 1.
PID namespaces are used in containers (lightweight virtualization solution) to migrate a container with a process tree, onto a different host system without any changes to PIDs.
This type of namespace provides abstraction and virtualization of network protocol services and interfaces. Each network namespace will have its own network device instances that can be configured with individual network addresses. Isolation is enabled for other network services: routing table, port number, and so on.
User namespaces allow a process to use unique user and group IDs within and outside a namespace. This means that a process can use privileged user and group IDs (zero) within a user namespace and continue with non-zero user and group IDs outside the namespace.
A cgroup namespace virtualizes the contents of the /proc/self/cgroup file. Processes inside a cgroup namespace are only able to view paths relative to their namespace root.
Cgroups are kernel mechanisms to restrict and measure resource allocations to each process group. Using cgroups, you can allocate resources such as CPU time, network, and memory.
Similar to the process model in Linux, where each process is a child to a parent and relatively descends from the init process thus forming a single-tree like structure, cgroups are hierarchical, where child cgroups inherit the attributes of the parent, but what makes is different is that multiple cgroup hierarchies can exist within a single system, with each having distinct resource prerogatives.
Applying cgroups on namespaces results in isolation of processes into containers within a system, where resources are managed distinctly. Each container is a lightweight virtual machine, all of which run as individual entities and are oblivious of other entities within the same system.
The following are namespace APIs described in the Linux man page for namespaces:
clone(2) The clone(2) system call creates a new process. If the flags argument of the call specifies one or more of the CLONE_NEW* flags listed below, then new namespaces are created for each flag, and the child process is made a member of those namespaces.(This system call also implements a number of features unrelated to namespaces.) setns(2) The setns(2) system call allows the calling process to join an existing namespace. The namespace to join is specified via a file descriptor that refers to one of the /proc/[pid]/ns files described below. unshare(2) The unshare(2) system call moves the calling process to a new namespace. If the flags argument of the call specifies one or more of the CLONE_NEW* flags listed below, then new namespaces are created for each flag, and the calling process is made a member of those namespaces. (This system call also implements a number of features unrelated to namespaces.) Namespace Constant Isolates Cgroup CLONE_NEWCGROUP Cgroup root directory IPC CLONE_NEWIPC System V IPC, POSIX message queues Network CLONE_NEWNET Network devices, stacks, ports, etc. Mount CLONE_NEWNS Mount points PID CLONE_NEWPID Process IDs User CLONE_NEWUSER User and group IDs UTS CLONE_NEWUTS Hostname and NIS domain name
We understood one of the principal abstractions of Linux called the process, and the whole ecosystem that facilitates this abstraction. The challenge now remains in running the scores of processes by providing fair CPU time. With many-core systems imposing a multitude of processes with diverse policies and priorities, the need for deterministic scheduling is paramount.
In our next chapter, we will delve into process scheduling, another critical aspect of process management, and comprehend how the Linux scheduler is designed to handle this diversity.






