


















In this book, we will go on a journey through the broad land of algorithms and data structures, taking a ride on the comfortable vehicle that is Clojure programming language.
First, we will take a look at arrays, exploring their particular structures to tackle problems as interesting as compression, fractal drawing, multithreading, and call stacks.
Then we will elaborate on linked lists, transforming them in to doubly linked lists. We will do this to speed up access to their elements, build parsers, and devise fast random access.
The next step of our trip will concern trees of data. We'll show you how to implement self-balancing red-black trees, how to design efficient key-value stores — thanks to B-trees (way to go in order to design undo-capable text editors), and lastly, a methodology to construct autocomplete text typing systems.
After that, we'll focus on exploring some optimization and machine-learning techniques. We will see how to set up a recommendation engine, the way to go to optimize a problem where costs and profits are involved, a methodology to find the best possible paths in graphs, and how to summarize texts.
Then we'll study the topic of logic programming, analyzing some website traffic logs to detect visitors of interest to us. Doing this, we'll dive into the problem of type inferencing for the Java language, and simulate a turn of a checkers game.
At that point, we'll talk about asynchronous programming as a means of tackling difficult problems. We'll build a tiny web spider, design an interactive HTML5 game, and design a complex online taxi-booking solution.
The last rally point of this trip, but certainly not the least, is that we'll have a look at the higher order functions and transducers at the heart of Clojure. We'll design a recursive descent parser using a trampoline, build a reusable mini firewall thanks to transducers, and lastly, explore the continuation passing style as a tool to design a simple unification engine.
This will be quite a tour, in which we will bring to life various real-world use cases related to the essential theory of computing as far as data structures and algorithms are involved, which are all served by the high expressive power of Clojure. By the end of this book, you'll be familiar with many of the advanced concepts that fuel most of the nontrivial applications of our world while you enhance your mastery of Clojure!
Compressing a byte array is a matter of recognizing repeating patterns within a byte sequence and devising a method that can represent the same underlying information to take advantage of these discovered repetitions.
To get a rough idea of how this works, imagine having a sequence as:
["a" "a" "a" "b" "b" "b" "b" "b" "b" "b" "c" "c"]
It is intuitively more efficient to represent this as:
[3 times "a", 7 times "b", 2 times "c"]
Now, we are going to use a methodology based on a well-known algorithm, that is, the LZ77 compression method. LZ77 is, despite being quite old, the basis of most of all the well-known and currently used compression methods, especially the Deflate algorithm.
Note
Deflate is at the heart of the ZIP family of compression algorithms. It uses a slightly modified version of LZ77 plus a special encoding, that is, the Huffman encoding.
The point of LZ77 is to walk a sequence and recognize a pattern in the past elements that will occur in the upcoming elements, replacing those with a couple of values: how many elements should go backwards in order to locate the recurring pattern, which is called "distance"; and how long is the recurring pattern, which is labeled as "length".
The iteration of the LZ77 compression would look as follows:
At any point of time, the algorithm is processing a particular element, which is located at the current position. Consider a window of the size n, as a set of n elements preceding the one that is occupying current position, and consider lookahead as the rest of the elements up until the input's end.
Begin with the first element of the input.
Move on to the next element.
Find in the window (that is, past n elements), the longest pattern that can be found in lookahead.
If such a sequence is found, consider distance as the location where, the matching sequence was found, expressed in regards to the current position, consider length as the length of the matching pattern, and proceed with the two following actions:
Replace the match in lookahead by "distance" and "length".
Move forward using the "length" elements and resume algorithm execution at step 4.
Otherwise, resume at step 3.
The procedure to uncompress is as follows:
Walk the compressed sequence.
If the "distance" and "length" are found, go back to the "distance" elements and replace this couple with the "length" elements.
If not, lay out the element that you've found.
Let's see this in action in Clojure!
First of all, here is the
nsdeclaration containing the Clojure facilities that we are going to use:(ns recipe1.core (:require [clojure.set :as cset])) ;; => we'll need set operations later on.
Let's begin by working on the uncompressing part. First of all, we need an
expandfunction that takes the source array as a vector of the elementsdistanceandlengthand generates a repetition of a sub-vector of the lastdistancecharacters from the source array until the length is reached:(defn expand [the-vector distance length] (let [end (count the-vector) start (- end distance) ;;=> Here we go backwards 'distance' elements. pattern (subvec the-vector start end)] ;=> We have our pattern. (into [] (take length ;=> We exactly take "length" from (cycle pattern))))) ;; an infinite repetition of our pattern.
Now, let's define
un-LZ77usingexpandfunction while walking through a sequence of bytes:(defn un-LZ77 [bytes] (loop [result [] remaining bytes] ;;=> We recur over the contents of the array. (if (seq remaining) (let [current (first remaining) the-rest (rest remaining)] ;=> Current element under scrutiny; (if-not (vector? Current) ;=> If it is not a vector, add to result (recur (conj result ;; the very element, and move on. current) the-rest) (recur (into result (expand result ;;=> This is a vector, then we'll expand here and move on (current 0) (current 1))) the-rest))) result))) ;;=> end of recursion, return result.
Now let's address the topic of compressing. First of all, we need to grab all sub-vectors, as we'll have to find matches between window and lookahead and then pick the longest one among them:
(defn all-subvecs-from-beginning ;;=> this function will generate a set of all sub-vectors starting ;; from begin [v] (set (map #(subvec v 0 %) ;;=> we apply subvec from 0 to all indices from 1 up to the size ;; of the array + 1. (range 1 (inc (count v)))))) (defn all-subvecs ;;=> this function will generate all [v] ; sub-vectors, applying (loop [result #{} ;; all-subvecs from beginning to ;; all possible beginnings. remaining v] (if (seq remaining) (recur (into result (all-subvecs-from-beginning remaining)) (into[] (rest remaining))) ;;=> We recur fetching all sub-vectors for next beginning. result))) ;;=> end of recursion, I return result.
Now we define a function to grab the longest match in
left arraywith the beginning ofright array:(defn longest-match-w-beginning [left-array right-array] (let [all-left-chunks (all-subvecs left-array) all-right-chunks-from-beginning ;;=> I take all sub-vectors from left-array (all-subvecs-from-beginning right-array) ;;=> I take all sub-vectors from right-array all-matches (cset/intersection all-right-chunks-from-beginning all-left-chunks)] ;;=> I get all the matchings using intersection on sets (->> all-matches (sort-by count >) first))) ;=> Then I return the longest match, sorting them ;; by decreasing order and taking the first element.
With the longest match function in hand, we need a function to tell us where where is this match exactly located inside the window:
(defn pos-of-subvec [sv v] {:pre [(<= (count sv) (count v))]} ;;=> I verify that sv elements are less than v's. (loop [cursor 0] (if (or (empty? v) ;;=> If on of the vectors is empty (empty? sv) (= cursor (count v))) ;; or the cursor ended-up exiting v, nil ;; we return nil (if (= (subvec v cursor ;; => If we found that the v sub-vector (+ (count sv) ;; beginning with cursor up to sv count cursor)) sv) ;; is equal to sv cursor ;; we return cursor, this is where the match is. (recur (inc cursor)))))) ;=> We recur incrementing the cursor
Armed with the toolbox we've built so far, let's devise an LZ77 step:
(defn LZ77-STEP [window look-ahead] (let [longest (longest-match-w-beginning window look-ahead)] ;;=> We find the Longest match, (if-let [pos-subv-w (pos-of-subvec longest window)] ;;=> If there is a match we find its position in window. (let [distance (- (count window) pos-subv-w) ;;=> the distance, pos-subv-l (pos-of-subvec longest look-ahead) ;;=> the position of the match in look-ahead the-char (first (subvec look-ahead (+ pos-subv-l (count longest))))] ;;=> the first element occuring after the match {:distance distance :length (count longest) :char the-char}) ;;=> and we return information about match {:distance 0 :length 0 :char (first look-ahead)}))) ;;=> We did not find a match, we emit zeros for "distance" ;; and "length", and first element of lookahead as first char ;; occurring after the (non-)match.
Finally, we will write the main LZ77 compression function as follows:
(defn LZ77 [bytes-array window-size] (->> (loop [result [] cursor 0 window [] look-ahead bytes-array] ;;=> we begin with position 0; and everything as look-ahead. (if (empty? look-ahead) result ;;=> end of recursion, I emit result. (let [this-step-output (LZ77-STEP window look-ahead) distance (:distance this-step-output) length (:length this-step-output) literal (:char this-step-output) ;;=> We grab informations about this step output raw-new-cursor (+ cursor length 1) new-cursor (min raw-new-cursor (count bytes-array)) ;;=> We compute the new-cursor, that is, where to go in the next ;; step ;;which is capped by count of bytes-array new-window (subvec bytes-array (max 0 (inc (- new-cursor window-size))) new-cursor) ;;=> new window is window-size elements back from new cursor. new-look-ahead (subvec bytes-array new-cursor )] ;;=> new look-ahead is everything from new cursor on. (recur (conj result [distance length] literal) new-cursor new-window new-look-ahead)))) ;; and we recur with the new elements. (filter (partial not= [0 0])) ;;=> We eliminate the entries related to non-matches (filter (comp not nil?)) ;;=> and any nils (into []))) ;;=> and make a vector out of the output.
That's it! Now, let's see our code in action. Input into your REPL as follows:
(LZ77 ["a" "b" "c" "f" "a" "b" "c" "d"] 5) ;; => ["a" "b" "c" "f" [4 3] "d"] (un-LZ77 ["a" "b" "c" "f" [4 3] "d"]) ;; => ["a" "b" "c" "f" "a" "b" "c" "d"]
Triangles are a particular matrix type. Each line contains exactly as many nonzero elements as the line index in the matrix. Here is a sample triangle depicted as a vector of vectors in Clojure:
[[1 0 0 0 0 0 0] [1 1 0 0 0 0 0] [1 1 1 0 0 0 0] [1 1 1 1 0 0 0] [1 1 1 1 1 0 0] [1 1 1 1 1 1 0] [1 1 1 1 1 1 1]]
Now, we can simply omit the zeros altogether and get a real triangle, graphically speaking:
[[1] [1 1] [1 1 1] [1 1 1 1] [1 1 1 1 1] [1 1 1 1 1 1] [1 1 1 1 1 1 1] [1 1 1 1 1 1 1 1 1]]
Pascal's triangle is a matrix whose elements are computed as the sum of the elements that are directly above it and the element to the left of the elements that are directly above it. The very first element is 1. This matrix was devised by Pascal as a means of computing the powers of binomials. Here's a Pascal's triangle for up to seven lines:
[[1] [1 1] [1 2 1] [1 3 3 1] [1 4 6 4 1] [1 5 10 10 5 1] [1 6 15 20 15 6 1]]
If we look at this Pascal's triangle, then a binomial, let's say (a+b), elevated to the power 4 is computed by extracting the coefficient from the row with index 4 (first row is having index 0. The resulting polynomial is: a4b+4a3b+6a2b2+4ab3+ab4.
Now, it happens that plotting odd elements from a Pascal's triangle yields a fractal, that is, an image that infinitely repeats itself.
Note
Such a fractal derived from plotting the odd elements of a Pascal's triangle is known as the Sierpinski triangle.
If you closely watch the triangle's structure, you'll notice that each line is symmetrical. As such, for the sake of efficiency, you only have to compute half of a line at a time and append it to its own mirrored copy to get the whole line.
Besides, as our main purpose is to draw fractals, we'll have to generate a huge Pascal's triangle, in order to have a proper image. Doing so will make us soon hit number limitations and we'll have to circumvent this. Luckily, summing the remainder of a division of two by two numbers leads to the same even properties, as if you've summed those very numbers. Then, our implementation will rely on this to come up with sufficiently big images; we'll create Pascal's triangles with the sums of the remainder of the division by two.
First of all we'll need to import, along with our
nsdeclaration, some Java facilities to help us build the fractal and write it to a file:(ns recipe2.core (:import (java.awt image.BufferedImage Color) ;=> so we can plot. (javax.imageio ImageIO) (java.io File))) ;=> so we can write to a file.Let's write a function to compute a particular row in a Pascal's triangle, As we've discussed, in a Pascal's triangle you compute a row of a particular index based on the one located directly above it (of the preceding index), that's why this function takes one row as input. Here we pass a
yieldfunction, permitting it to compute an element out of its immediately preceding neighbor and the element to the left of the preceding neighbor. Each time, we compute half a line and append it to its reverse:(defn pascal-row-step [yield pascal-row] ;=> pascal-row is the one above the row we're computing {:pre [(> (get pascal-row 0) 0)]} ;=> We can only start from [1]! (let [cnt-elts (count pascal-row) half-row (subvec pascal-row 0 (inc (double (/ cnt-elts 2)))) ;;=> We compute half the above row padded-half-row (into [0] half-row) ;;=> and add a 0 to the beginning, as we'll use it in computation half-step (vec (map (comp (partial apply yield) vec) (partition 2 1 padded-half-row))) ;;=> we compute the first half, summing the above element ;; and the element at the left of the above one. other-half-step (vec (if (even? cnt-elts) (-> half-step butlast reverse) (-> half-step reverse)))] ;;=> the mirror of the half we computed. If count elements is ;; even, we omit the last element from half-step. (into half-step other-half-step))) ;;=> we return half to which we append the mirror copy.Now, we'll build the whole Pascal's triangle parameterized with the
yieldfunction:(defn pascal-rows [yield row-number] (loop [nb 0 result [] latest-result [1]] ;=> We'll loop using pascal-row-step, ;;=> keeping track of the last ;;computed line at each step of the recursion. (if (<= nb row-number) ;;=> the counter did not still reach the end (recur (inc nb) (conj result latest-result) (pascal-row-step yield latest-result)) ;;=> We recur incrementing the counter, feeding the new line to ;; result and keeping track of the last computed line. result))) ;;=> end of the recursion, emitting result.We will also prepare a
yieldfunction to compute the remainder of the sum of two numbers:(defn even-odd-yield [n1 n2] (mod (+ n1 n2) 2))
We will prepare a helper function to generate the fractals:
(def gr-triangles (partial pascal-rows even-odd-yield))
Now we can just launch the following to have our graphical 0-1 fractal representation:
(gr-triangles 10)
With
gr-trianglesunder our belt, we have to plot points at the positions that hold1. For this, we'll consider the cords of such positions to be the index of line and the index of elements in the vector held by this line that have the value1:(defn draw [size] (let [img (BufferedImage. size size BufferedImage/TYPE_INT_ARGB) ;;=> Creating img as a Buffered Image plot-rows (gr-triangles size) ;;=> computing the triangle of 0 and 1 plots (for [x (range 0 size) y (range 0 x)] (if (= 1 (get (get plot-rows x) y)) [x y])) ;;=> we save the positions holding 1 in vectors. As the structure ;; is triangular; ;; the first counter, "x" goes up to "size", and the second one, ;; "y", ;; goes up to "x" gfx (.getGraphics img)] ;;=> we get the graphics component, where to draw from the Java ;; Object. (.setColor gfx Color/WHITE) (.fillRect gfx 0 0 size size ) ;;=> we set a white background for the image. (.setColor gfx Color/BLACK) ;;=> We set the pen color to black again (doseq [p (filter (comp not nil?) plots)] (.drawLine gfx (get p 0) (get p 1) (get p 0) (get p 1))) ;;=> We plot, by drawing a line from and to the same point. (ImageIO/write img "png" (File. "/your/location/result.png")))) ;;=> and we save the image as a png in this location. ;; Be sure to set a correct one when running on your machine !
Here is a zoomed-out image generated by this function of the size 10,000:

Here is a zoomed-in view of some parts of it:

Here, the same triangles appear over and over again as you zoom in on the image.
Time-sharing is about sharing a computing facility between multiple concurrent processes. At its very basic version, a scheduler decides , which one of these competing processes to execute at every single quantum of time. This way, even a single processor core, only capable of sequential operation, is able to spawn multiple threads, as if they were being executed in parallel.
One method of preventing race conditions, that is, multiple processes concurrently reading and writing wrong versions of the same shared place in memory, is locking. Imagine, for example, that there are two processes incrementing the same shared counter. Process 1 takes the value of the counter and overwrites it with the value + 1. If, meanwhile, process 2 does the same thing – that is, it reads the same version of the counter that process 1 reads for the very first time and overwrites it with the same value + 1 – you'd end up with the counter that will only be incremented once. Hence, locking this portion of code makes process 2 wait for process 1 until it finishes reading and writing, and only when process 1 is done and sets the lock free, process 2 will be allowed to play its part, leading to the correct final value of the counter + 2.
Note
Managing locks can be too tedious. That's why it is often better to use high-level concurrency alternatives, such as those provided by Clojure: the software transactional memory (refs and atoms), agents, and core.async.
First of all, we'll begin importing some libraries that we will use:
(ns recipe3.core (:require [instaparse.core :as insta]) ;;=> For parsing the code of our ;processes (:require [clojure.zip :as z]) ;;=> To walk the parse-trees and generate processes instructions. (:require [clojure.pprint :refer :all])) ;;=> an Alias to easily pretty print our outputs.Note
Instaparse (https://github.com/engelberg/instaparse) is a parser generator written in Clojure. To explain all of the mechanism behind Instaparse is beyond the scope of this book, but you should know that it handles context-free grammar (CFG) and generates parse trees of your input programs according to these grammar concepts.
To be able to pretty-print our output in the REPL, let's define an alias for
clojure.pprint/pprint, so that we can make it more conveniently:(def p pprint)
As we'll be spawning processes with instructions of their own, let's define a minimal language that
instaparsewill be able to interpret for us. Our language instructions for a single process are as follows:heavy-op op1; light-op op2; lock l1; medium-op op3; unlock l1;
The previous snippet is self-explanatory. Our language only contains three types of operations:
heavy-op, which are sorted according to the effort they need in order to be fully processed by the scheduler:heavy-op,medium-op, and finallylight-op. Besides, we are able to lock and unlock a portion of our programs with thelockandunlockinstructions. Each one of these instructions needs you to specify an identifier, so that they can be recognized in the scheduler output.The grammar for such a language is:
(def r3-language "S = INSTRS INSTRS = ((INSTR | LOCKED-INSTRS) <optional-whitespace>)* INSTR = HEAVY-OP | MEDIUM-OP | LIGHT-OP HEAVY-OP = <optional-whitespace> 'heavy-op' <whitespace> ID <SEP> MEDIUM-OP = <optional-whitespace> 'medium-op' <whitespace> ID <SEP> LIGHT-OP = <optional-whitespace> 'light-op' <whitespace> ID <SEP> LOCKED-INSTRS = LOCK INSTRS UNLOCK LOCK = <optional-whitespace> 'lock' <whitespace> ID <SEP> UNLOCK = <optional-whitespace> 'unlock' <whitespace> ID <SEP> ID = #'[a-zA-Z0-9]+' PRIORITY = #'[0-9]+' whitespace = #'\\s+' optional-whitespace = #'\\s*' SEP = #'\\s*' ';'")
Note that identifiers between angle brackets will not be seen in the parse tree, so there's no use referring to the
white-spacetags, for instance.Let's see what would be the Instaparse output for the program we wrote in the preceding code. For this, just type the following in your REPL:
(p (insta/parse (insta/parser r3-language) "heavy-op op1; light-op op2; lock l1; medium-op op3; unlock l1;")) And you'll get : [:S [:INSTRS [:INSTR [:HEAVY-OP "heavy-op" [:ID "op1"]]] [:INSTR [:LIGHT-OP "light-op" [:ID "op2"]]] [:LOCKED-INSTRS [:LOCK "lock" [:ID "l1"]] [:INSTRS [:INSTR [:MEDIUM-OP "medium-op" [:ID "op3"]]]] [:UNLOCK "unlock" [:ID "l1"]]]]]
We need to transform these nested vectors in to instructions. First of all, we will make use of the very handy instaparse function
transformto eliminate the rules tags and get a more useful representation of our instructions.transformfunction takes a tag and applies a function to the elements next to it in the vector that this tag refers to:(defn gen-program [parser program] (insta/transform {:S identity :INSTRS (fn [& args] (vec args)) :INSTR identity :HEAVY-OP (fn [x y] {:inst-type :heavy-op :inst-id (get y 1)}) :MEDIUM-OP (fn [x y] {:inst-type :medium-op :inst-id (get y 1)}) :LIGHT-OP (fn [x y] {:inst-type :light-op :inst-id (get y 1)}) :LOCKED-INSTRS (fn [& args] (vec args)) :LOCK (fn [x y] {:inst-type :lock :inst-id {:lock (get y 1)} }) :UNLOCK (fn [x y] {:inst-type :unlock :inst-id {:unlock (get y 1)}})} ;;=> This map tells 'transform' how to transform elements next to ;; each tag. (parser program))) ;; The raw parse tree emitted by Insaparse.Here is the output of
gen-program. Input the following code in the REPL:(p (gen-program (insta/parser r3-language) "heavy-op op1; light-op op2; lock l1; medium-op op3; unlock l1;"))You'll get the following output:
[{:inst-type :heavy-op, :inst-id "op1"} {:inst-type :light-op, :inst-id "op2"} [{:inst-type :lock, :inst-id {:lock "l1"}} [{:inst-type :medium-op, :inst-id "op3"}] {:inst-type :unlock, :inst-id {:unlock "l1"}}]]To get rid of the nesting that we still see here, we are going to use a zipper, which is a Clojure facility to walk trees. Basically, we will loop all the nested vector elements and only take maps, so that we end up with a nice, flat program structure. As this will be our actual process, we'll also append a
process-idattribute and apriorityattribute to its output:(defn fire-a-process [grammar program process-id priority] (let [prsr (insta/parser grammar) ;;=> the parser vec-instructions (gen-program prsr program) ;;=> the nested structure zpr (z/vector-zip vec-instructions)] (loop [result [] loc (-> zpr z/down)] (if (z/end? loc) ;;=> the end of recursion, no more nodes to visit {:process-id process-id :instructions result :priority priority} ;;=> We generate the process (recur (if (map? (z/node loc)) ;;=> We only append to result the elements of type 'map' (conj result (z/node loc)) result) ;;=> else we pass result as is in the recursion (z/next loc)))))) ;=> and we recur with the next element.Here is a process spawned by our program named
:process-1that has the priority10. Input the following in your REPL:(fire-a-process r3-language "heavy-op op1; light-op op2; lock l1; medium-op op3; unlock l1;" :process-1 10)You'll get the following output:
{:process-id :process-1, :instructions [{:inst-type :heavy-op, :inst-id "op1"} {:inst-type :light-op, :inst-id "op2"} {:inst-type :lock, :inst-id {:lock "l1"}} ;;=> note that ':inst-id' of locks are {':lock' or ':unlock' id}, ;; so a locking and an un-locking instructions are not mistaken ;; one for another. {:inst-type :medium-op, :inst-id "op3"} {:inst-type :unlock, :inst-id {:unlock "l1"}}], :priority 10}Now, we need to set effort for each of our instructions, that is, how many processor cycles each one of them takes to be executed:
(def insts-effort {:heavy-op 10 :medium-op 5 :light-op 2 :lock 1 :unlock 1})Now we'll concern ourselves with locking. First of all, we need to find the indices of locking instructions in our instructions vector:
(defn all-locks-indices [instructions] ;;=> 'instructions' is the ':instructions vector' of the output of ;; fire-process. (let [locks (filter #(= (:inst-type %) :lock) instructions) ;;=> We find out all the 'locks' in 'instructions'. lock-indices (map (fn [l] {:lock-id (l :inst-id) :lock-idx (.indexOf instructions l)}) locks)] ;; And for every lock we find out its index in 'instructions, ;; and prepare a map with it. lock-indices)) ;;=> output of this is : ({:lock-id {:lock "l1"}, :lock-idx 2})With our locks recognized, we can tell which lock every instruction depends on. This is basically done by finding out which locks have indices inferior to the instruction index:
(defn the-locks-inst-depends-on [instructions instruction] (let [the-inst-idx (.indexOf instructions instruction) the-lock-idxs (all-locks-indices instructions)] (into [] (->> the-lock-idxs (filter #(> the-inst-idx (:lock-idx %) )) (map :lock-id)))))We'll need a map that maintains the state of locks so the scheduler can track the locking and unlocking activities during the program execution with. We'll define
lockandun-lockfunctions to do this:(defn lock "locks lock lock-id in locks map" [locks process-id lock-id] (assoc locks lock-id {:locker process-id :locked true})) (defn unlock "unlocks lock lock-id in locks map" [locks process-id lock-id] (assoc locks lock-id {:locker process-id :locked false})) ;;=> The locks state contains its locked state and which process ;; did lock it.The locker process information, manipulated in the previous step is important. As some process' instruction can only be denied access to a shared resource by locks set by other processes contains, we need to track which is locking what. The
is-locked?function relies on this mechanism to inform whether an instruction is locked at any point in time, so it cannot be fired by the scheduler:(defn is-locked? [process-id instructions locks instruction] (let [inst-locks (the-locks-inst-depends-on instructions instruction)] (some true? (map #(and (not= process-id ((get locks %) :locker)) ((get locks %) :locked)) inst-locks)))) ;;=> If some of the locks the instruction depend on are locked (:locked true) ;; and the locker is not its process, then it is considered as ;; locked.Let's focus on the scheduler now. Imagine that some parts of a process have already been assigned some quanta of time. We need a map to maintain a state for all the processes regarding the parts that already have been processed so far. We'll call this map
scheduled. Let's say that this map should look like the following:[{:process-id :process-1 :instructions [{:times [1 2 3], :inst-id "op1", :inst-type :heavy-op} {:times [4 5 6], :inst-id "op2", :inst-type :medium-op}]}{:process-id :process-id :process-2 :instructions [{:times [7 8], :inst-id "op1", :inst-type :heavy-op} {:times [9 10], :inst-id "op2", :inst-type :medium-op}]}] ;;=> ':times' contain vectors of the time quantums allocated to ;; the instruction.We'll prepare a helper function,
scheduled-processes-parts, that'll count the number of quanta already allocated, and this will be handy in knowing whether an instruction is complete:(defn scheduled-processes-parts [scheduled] (into [] (map (fn [p] {:process-id (:process-id p) :instructions (into [] (map (fn [i] {:inst-id (:inst-id i) :inst-type (:inst-type i) :count (count (:times i))}) (:instructions p)))}) scheduled))) ;;=> this functions just adds :count n to the map maintained in ;;"scheduled"We'll use this function to implement
incomplete-instruction?,incomplete-process?, andmore-incomplete-processes?that we'll use later on:(defn incomplete-instruction? [instruction-w-count] (let [instr-effort (insts-effort (instruction-w-count :inst-type)) instr-count (instruction-w-count :count)] (< instr-count instr-effort))) (defn incomplete-process? [process-w-counts] (let [instrs-w-count (process-w-counts :instructions)] (some true? (map incomplete-instruction? instrs-w-count)))) (defn more-incomplete-processes? [processes-w-count] (some true? (map incomplete-process? processes-w-count))) ;=> processes-w-count is just another name for the "scheduled" ;; state map.Diving deeper into the implementation, let's now look at a single process and define a function that finds which instruction is to be fired if the scheduler decides to allocate a quantum to it. This translates to the first incomplete instruction if it is non-locked, that is, none of its locks have been set to
lockedby another process:(defn find-inst-to-be-fired-in-process [locks process-id the-process-instructions the-process-scheduled-parts] (let [p-not-locked-instrs (set (->> the-process-instructions (filter #(not (is-locked? process-id the-process-instructions locks %))))) ;;=> A set of not locked instructions p-incomplete-instrs (set (->> (:instructions the-process-scheduled-parts) (filter incomplete-instruction?) (map #(dissoc % :count)))) ;;=> A set of incomplete instructions fireable-instrs (clojure.set/intersection p-not-locked-instrs p-incomplete-instrs) ;;=> Their intersection instr-id-to-fire (->> fireable-instrs (sort-by #(.indexOf the-process-instructions %) < ) (first) (:inst-id))] ;;=> The first on of them instr-id-to-fire))Now, let's write
progress-on-process!, which considers one particular process, fires its fireable instruction — as found by the preceding function, and updates alllocksandscheduledstates. This is quite a long function, as it is the heart of the scheduler:(defn progress-on-process! [locks-ref scheduled-ref the-process quantum] (let [the-process-instrs (the-process :instructions) processes-scheduled-parts (scheduled-processes-parts @scheduled-ref) the-process-scheduled-parts (->> processes-scheduled-parts (filter #(= (:process-id %) (:process-id the-process))) (first))] ;;=> Here we prepare the processes scheduled parts and take only ;; the relevant to the particular 'process-id'. (if-let [the-instr-to-fire-id (find-inst-to-be-fired-in-process @locks-ref (:process-id the-process) the-process-instrs the-process-scheduled-parts )] ;;=> If there is one instruction in "process-id" to be fired; (dosync ;;=> We use the refs, because we need to do transactions involving ;; both "scheduled" and "locks" (let [the-instr-to-fire (->> the-process-instrs (filter #(= (:inst-id %) the-instr-to-fire-id)) (first))] ;;=> We get the entry relevant to this instruction-id (cond (= (:inst-type the-instr-to-fire) :lock ) (alter locks-ref lock (:process-id the-process) the-instr-to-fire-id) (= (:inst-type the-instr-to-fire) :unlock ) (alter locks-ref unlock (:process-id the-process) {:lock (:unlock the-instr-to-fire-id)}))) ;;=> If it is a "lock" or "unlock", We update the "locks" state ;; map (let [p-in-scheduled (->> @scheduled-ref (filter #(= (:process-id %) (:process-id the-process))) (first)) ;;=> To update the "scheduled" ref, we begin by finding the ;; ':process-d' in the processes vector instr-in-p-in-scheduled (->> (get p-in-scheduled :instructions) (filter #(= (:inst-id %) the-instr-to-fire-id)) (first)) ;; Then We find the instruction in this process idx-p-in-scheduled (max 0 (.indexOf @scheduled-ref p-in-scheduled)) idx-inst-in-p-in-scheduled (max 0 (.indexOf (get p-in-scheduled :instructions) instr-in-p-in-scheduled)) ;;=> We compute the index of the instruction; or we set it at 0 ;; if it is not found, which means it is the first time it is ;; scheduled. times-in-inst-in-p-in-scheduled (get (get (p-in-scheduled :instructions) idx-inst-in-p-in-scheduled) :times ) ;;=> We get the times vector in "scheduled" related to this ;; instruction _ (alter scheduled-ref assoc-in [idx-p-in-scheduled :instructions idx-inst-in-p-in-scheduled :times] (conj times-in-inst-in-p-in-scheduled quantum))]) ;;=> And using assoc-in, with indices and keys as a "path ;; vector", we Update the "scheduled" ref with times vector ;; to which we Append the current "quantum". true) ;;=> If we were able to find a fireable instruction, ;; we issue "true". false))) ;; => Else we issue "false".The following functions will help us prepare empty
locksandscheduledmaps, which are to be used byprogress-on-process!:(defn prepare-scheduled [processes] (into [] (->> processes (map (fn[p] {:process-id (:process-id p) :instructions (into [] (->> (:instructions p) (map (fn [i] (assoc i :times [])))))}))))) ;;=> We prepare "scheduled" as being the same thing as the ;; "processes" map ;; with empty ":times" vectors added. (defn prepare-locks-for-a-p [a-process] (let [locks (filter #(= (:inst-type %) :lock ) (:instructions a-process))] (reduce (partial apply unlock) {} (map (fn [l] [(:process-id a-process) (:inst-id l)]) locks)))) ;;=> A helper function that will prepare "locks" set to false for ;; instructions related to a process" (defn prepare-locks [processes] (reduce merge (map prepare-locks-for-a-p processes))) ;;=> Applying "prepare-locks-for-a-p", we generate locks for all ;; processes that would run concurrently.Equipped with all these functions, we must address the problem of process selection for the allocation of each quantum of time. We must give each process an opportunity to access the scheduler quanta according to its priority. For this purpose, we will construct an infinite sequence of holding repetitions of a process ID as many times as their priority values. In this, a process with higher priority will always come before another with lower priority. Suppose we have process
p1with priority 3, processp2with priority 2, and processp3with priority 1, then a sequence presenting the cycling that we described previously would be:[p1 p1 p1 p2 p2 p3 p1 p1 p1 p2 p2 p3....]
As the time quantums flow, the scheduler will have to pick at each step an element, cycling through the weighted cycling list, which we just saw, to be sure it is fair toward the process's priority.
The following functions create the priority-weighted cycling process IDs:
(defn gen-processes-cycles [processes] (let [sorted-procs-by-prio (sort-by :priority > processes) procs-pattern (mapcat #(repeat (:priority %) %) sorted-procs-by-prio)] ;;=> A pattern is a single repetition "priority" times of each ;; process (cycle procs-pattern))) ;;=> Generates an infinite sequence like we described above.Locking programs may lead to infinite waiting. To tackle this problem, we will set a time-out for our scheduler, which will be twice the time needed by all the processes if they were to be executed sequentially, one after the other. This function does just that:
(defn process-sequential-time [a-process] (let [instructions (a-process :instructions) inst-types (map :inst-type instructions) lengths (map #(get insts-effort %) inst-types)] (reduce + lengths))) ;;=> We get instruction-types, grab the efforts from the "insts- ;; effort" ;; map and sum them all up using reduce.Finally, we can write our scheduler. While there are incomplete processes left to be scheduled and before the current quantum reaches time-out, the scheduler will cycle the weighted processes cycles, pick one process, and call
progress-on-a-process!on it. Note that we launch this on several programs as we are implementing time-sharing to do multithreading:(defn schedule-programs [language programs] ;;=> programs are maps : {:program "the textual program", ;; :process-id the-process-id ;; :priority the-process-priority } (let [processes (into [] (map #(fire-a-process language (:program %) (:process-id %) (:priority %)) programs)) ;;=> Processes are constructed timeout (* 2 (reduce + (map process-sequential-time processes))) ;;=> "timeout" is the total length of all processes executed one ;; after the other. locks (ref (prepare-locks processes)) scheduled (ref (prepare-scheduled processes)) processes-cycles (gen-processes-cycles processes)] ;;=> We prepare "locks" and "scheduled" refs, and the weighted ;; process repetitions that the scheduler will have to cycle ;; through (loop [quantum 0 remaining-processes processes-cycles] ;;=> We loop (if (and (more-incomplete-processes? (scheduled-processes-parts @scheduled)) (< quantum timeout)) (do (progress-on-process! locks scheduled (first remaining-processes) quantum) ;;=> progress on the selected process, with current "quantum" (recur (inc quantum) (next remaining-processes))) ;;=> Go to next iteration, incrementing quantum and cycling ;;=> through the The weighted processes cycles. @scheduled)))
Now, let's define two random programs and see how they perform. First, define them in your REPL:
(def programs [{:priority 3, :program "heavy-op op1;light-op op2;lock l1;medium-op op3;unlock l1;", :process-id :pr1} {:priority 1, :program "lock l1;medium-op op4;unlock l1;medium-op op5;", :process-id :pr2}])
Now, launch schedule-programs:
(p (schedule-programs r3-language programs))
By launching it, you'll get the following output:
[{:process-id :pr1, :instructions [{:times [0 1 2 4 5 6 8 9 10 12], :inst-type :heavy-op, :inst-id "op1"} {:times [13 14], :inst-type :light-op, :inst-id "op2"} {:times [16], :inst-type :lock, :inst-id {:lock "l1"}} {:times [17 18 20 21 22], :inst-type :medium-op, :inst-id "op3"} {:times [24], :inst-type :unlock, :inst-id {:unlock "l1"}}]} {:process-id :pr2, :instructions [{:times [3], :inst-type :lock, :inst-id {:lock "l1"}} {:times [7 11 15 27 31], :inst-type :medium-op, :inst-id "op4"} {:times [35], :inst-type :unlock, :inst-id {:unlock "l1"}} {:times [39 43 47 51 55], :inst-type :medium-op, :inst-id "op5"}]}]
Tip
Downloading the example code
You can download the example code files for all Packt books you have purchased from your account at http://www.packtpub.com. If you purchased this book elsewhere, you can visit http://www.packtpub.com/support and register to have the files e-mailed directly to you.
A call stack is a data structure that is built when a program runs. As function calls keep coming in, the information regarding their code is arranged in frames, that is, a frame per call or variable evaluation. And these frames are stacked up. The program execution is then a matter of "unwinding" these frames, that is, after a frame at the top of the stack has been evaluated, it is unstacked and the process resumes at the new frame that is now at the top of the call stack.
Here we will observe a simple rule to unwind: as the execution goes, if we unstack a variable, we store it, and when we encounter a function call to unstack, we store the return value of its call and pass to it the parameters that we've stored so far. The next figure explains this process:
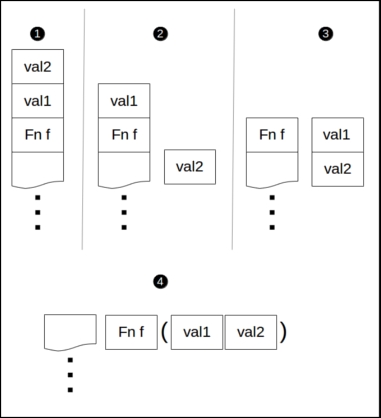
Unwinding the frames in a call Stack
First of all, let's define our
ns(namespace) incorporating all Clojure facilities that we will use:(ns recipe4.core (:require [instaparse.core :as insta]) ;;=> To parse our programs (:require [clojure.zip :as z]) ;;=> To walk and process parse trees (:require [clojure.pprint :refer :all]) ;;=> To pretty print results (:require [clojure.walk :as walk])) ;;=> To transform some nodes ;; in our programs' parse trees
We'll also alias
clojure.pprint/pprintso that we can easily pretty-print the results of our computations:(def p pprint)
We'll design a minimal language that will be parsed with
instaparse.Note
Instaparse (https://github.com/engelberg/instaparse) is a parser generator written in Clojure. Explaining the mechanism of Instaparse is beyond the scope of this book, but you should know it handles context-free grammars (CFG), and generates parse trees of your input programs according to these grammar concepts.
Our language will only be able to understand function calls. You can think of it as a kind of Lisp, but with no prefix notation; you can write your functions using the old mathematical way in this. Besides, our language is able to understand function declarations. Here is an example of what a program in this language looks like:
decl-fn f(x,y){ plus(x,y); }; plus(f(1,2),f(3,4));The functions without declarations are considered
primitiveorlibraryfunctions in our programs.Here is the
instaparsegrammar that is able to parse programs written in our minimal language:(def r4-language "S = ((FN-CALL|FN-DECL) <FN-SEP>)* FN-CALL = <optional-whitespace> ID <optional-whitespace> <left-paren> PARAMS-LIST <right-paren> PARAMS-LIST = <optional-whitespace> (ID|FN-CALL) (<optional-whitespace> <PARAMS-SEP> <optional-whitespace> (ID|FN-CALL))* FN-DECL = <optional-whitespace> 'decl-fn' <whitespace> ID <optional-whitespace> <left-paren> ARGS-LIST <right-paren> <optional-whitespace> <left-curly> FN-DECL-BODY <right-curly> ARGS-LIST = <optional-whitespace> ID (<optional-whitespace> <PARAMS-SEP> <optional-whitespace> ID)* FN-DECL-BODY = (FN-CALL <FN-SEP>)* left-paren = '(' right-paren = ')' left-curly = '{' right-curly = '}' ID = #'[a-zA-Z0-9]+' whitespace = #'\\s+' optional-whitespace = #'\\s*' FN-SEP = <optional-whitespace> ';' <optional-whitespace> PARAMS-SEP = <optional-whitespace> ',' <optional-whitespace>")Note that identifiers between angle brackets will not be shown in the parse tree, so there's no use of referring to
white-spacetags, for instance.Let's see what the parse tree of the program we previously wrote looks like. Issue the following code in your REPL:
(p (insta/parse (insta/parser r4-language) " decl-fn f(x,y){ plus(x,y); }; plus(f(1,2),f(3,4));"))After this step, you'll get the following output:
[:S [:FN-DECL "decl-fn" [:ID "f"] [:ARGS-LIST [:ID "x"] [:ID "y"]] [:FN-DECL-BODY [:FN-CALL [:ID "plus"] [:PARAMS-LIST [:ID "x"] [:ID "y"]]]]] [:FN-CALL [:ID "plus"] [:PARAMS-LIST [:FN-CALL [:ID "f"] [:PARAMS-LIST [:ID "1"] [:ID "2"]]] [:FN-CALL [:ID "f"] [:PARAMS-LIST [:ID "3"] [:ID "4"]]]]]]
Now we'll use the
instaparseandtransformfunctions to provide a more convenient representation of our parsed program.transformfunction replaces particular tags in the parse tree, applying a function to the rest of elements in the vector that contains those tags. Here is how we want to transform the parse trees:(defn gen-program [parser program] (into [] (insta/transform {:S (fn [ & args] args) :FN-CALL (fn [fn-id params] [:FN-CALL (fn-id 1) params]) :PARAMS-LIST (fn[& params] (into [] params) ) :FN-DECL (fn [_ decl-fn-id args body] [:FN-DECL (decl-fn-id 1) args body]) :ARGS-LIST (fn [& args] (into [] args)) :FN-DECL-BODY (fn [& body] (into [] body))} (parser program))))To better understand what this function does you can refer to its output, which is as follows. Input the following code in to your REPL:
(p (gen-program (insta/parser r4-language) "decl-fn f(x,y){ plus(x,y); }; plus(f(1,2),f(3,4));" ))After completing this step, you'll get the following output:
[[:FN-DECL "f" [[:ID "x"] [:ID "y"]] [[:FN-CALL "plus" [[:ID "x"] [:ID "y"]]]]] [:FN-CALL "plus" [[:FN-CALL "f" [[:ID "1"] [:ID "2"]]] [:FN-CALL "f" [[:ID "3"] [:ID "4"]]]]]]
With this representation of our program, we first need to know which functions are declared:
(defn get-fn-decls [program] (->> program (filter #(= :FN-DECL (get % 0))) ;;=> Take only instructions with :FN-DECL tag (into [])))Complementary to this function, we need a function that tells us which instructions (function calls) we have in our program:
(defn get-instructions [program] (->> program (filter #(not= :FN-DECL (get % 0))) ;;=> Take only instructions with no :FN-DECL tag. (into [])))Now we will focus on how to translate declared function calls. We need to exchange the reference to such calls with the bodies of declaration, in which we inject the parameters passed along with the call. Let's first see the declaration of a particular function:
(defn get-fn-id-decl [fn-decls fn-id] (->> fn-decls (filter #(= (get % 1) fn-id)) ;;=> Returns the fn-decl that matches the passed fn-id. (first))) ;;=> This function will return 'nil' if there is no ;; declaration found for it.Now we are going to implement
call-fn, which is a function that does the actual translation of a function call using its declaration (if we ever find any) and passed parameters:(defn call-fn [fn-decl fn-call] (let [decl-args-list (fn-decl 2) ;;=> we get the args in the declaration decl-body (fn-decl 3) ;;=> We get the body of the declaration. fn-call-params (fn-call 2)] ;;=> We get the passed parameters (if (not (= (count decl-args-list) (count fn-call-params))) [:arity-error-in-calling (fn-decl 1 )] ;;=> If the count of parameters and args mismatch, we say we have an arity error (let [replacement-map (zipmap decl-args-list fn-call-params)] ;;=> we prepare a replacement map for 'postwalk-replace': ;; zipmap builds a map containing keys from the first seq ;; 'decl-args-list' and vals from the second one 'fn-call-params'. (walk/postwalk-replace replacement-map decl-body))))) ;;=> 'postwalk-replace' will then change in 'decl-body' the ;; arguments 'decl-args-list' by corresponding paramters in ;; 'fn-call-params'Next, we will do the actual translation of the declared function calls and leave the non-declared functions as they are, assuming that they are
primitiveorlibraryfunctions. This is why we called theexpand-to-primitive-callsfunction:(defn expand-to-primitive-calls [program] ;;=> A program generated with 'gen-program' (let [fn-decls (get-fn-decls program) instructions (get-instructions program) ;;=> preparing function declarations and instructions . zpr (z/vector-zip instructions)] ;;=> A zipper to walk instructions. (loop [result instructions ;;=> We initially have our result set to be our instructions. loc (-> zpr z/down)] (if (-> loc z/end?) result ;;=> end of recursion. If no more nodes to visit, we emit result. (let [current-node (-> loc z/node)] ;;=> We store current node (if (= (get current-node 0 :FN-CALL)) ;;=> If it is a function call (if-let [the-decl (get-fn-id-decl fn-decls (get current-node 1))] ;;=> and it has a declaration associated with it (recur (walk/postwalk-replace {(-> loc z/node) (call-fn the-decl current-node)} result ) (-> loc z/next)) ;;=> we recur replacing this current-nod with ;; the function declaration along with the parameters. (recur result (-> loc z/next))) ;;=> else we recur leaving the function as is considering it ;; to be 'primitive'. (recur result (-> loc z/next)))))))) ;;=> or we recur leaving the instruction as is, because here ;; we only have a variable evaluation.At this particular point we are able to construct a call stack for an instruction:
(defn a-call-stack [a-call] (let [zpr (z/vector-zip a-call)] ;;=> A zipper to walk our call. (loop [result [] loc (-> zpr z/down)] (if (-> loc z/end?) result ;;=> End of the recursion, we emit result. (let [current-node (-> loc z/node)] ;=> we store the current node. (recur (if (and (not (vector? current-node)) (not= :FN-CALL current-node) (not= :ID current-node)) ;;=> If this is a literal, that is, not a vector, and not a tag, (conj result {(-> loc z/left z/node) current-node}) ;;=> I add it to the stack, along with the node at its left; ;;=> for instance, we'll have {:ID a-value} ;; or {:FN-CALL a value} result) ;; => Else we leave the stack as is. (-> loc z/next))))))) ; and we go to the next node.Finally, we will get to construct a stack for every instruction:
(defn program-call-stack [prog] (into [] (map a-call-stack (expand-to-primitive-calls prog))))
Let's see how it works. Type the following in to your REPL:
(p (program-call-stack (gen-program (insta/parser r4-language) "decl-fn f(x,y){ plus(x,y); }; plus(f(1,2),f(3,4)); f(4,5);" )))
The result of this would be:
[[{:FN-CALL "plus"} {:FN-CALL "plus"} {:ID "1"} {:ID "2"} {:FN-CALL "plus"} {:ID "3"} {:ID "4"}] [{:FN-CALL "plus"} {:ID "4"} {:ID "5"}]]
Here, the stack top comes last, as vectors in Clojure are way more efficiently accessed from the tail. This stack would be unwinded as follows:
This stack processes instruction 1.
Then it stores the value
4.Stores the values
3,4.Stores the value of
plus("3","4).Stores the values of
2,plus("3","4).Stores the values of
1,2,plus("3","4).Stores the values of
plus("1","2"),plus("3","4).Stores the values of
plus(plus("1","2"),plus("3","4)).Instruction 1 finishes returning
plus(plus("1","2"),plus("3","4)).Then it processes instruction 2.
Stores the value
5.Stores the values
4,5.Stores the value of
plus ("4","5").Instruction 2 finishes returning the value of
plus ("4","5").
